Supercharging Optimisation: How Artelys, FICO and NVIDIA cuOpt Join Efforts to Scale Up Energy System Optimisation
To address this, Artelys, FICO, and NVIDIA partner to explore a hybrid solver strategy combining FICO Xpress’s advanced CPU-based preprocessing and barrier methods with NVIDIA cuOpt GPU-accelerated linear programming (LP) and mixed-integer programming (MIP) engines. The goal: dramatically reduce solve times for some of the largest energy planning models ever built.
Using internal datasets built from authoritative sources including ENTSO-E Ten Year Network Development Plan (TYNDP) and the Pan-European Market Modelling Database for European Resource Adequacy Assessment (PEMMDB ERAA), the team solved massive unit commitment problems (UCP)—which involve both continuous and discrete decisions such as generator ramping and start-ups—under hybrid CPU-GPU workflows.
The results are striking. For the largest models, solving time dropped from over 6 hours on CPU-only pipelines to under 20 minutes using the hybrid approach—up to 20x speedups. These gains were driven by a combination of Xpress’s powerful presolve engine and cuOpt’s GPU-accelerated solver, highlighting how CPU-GPU hybrid solver pipelines can overcome key performance barriers.
This blog shares what was done, how it was done, and what it reveals about the future of large-scale optimisation in energy systems—and beyond. Visit also FICO blog post to discover more about it.
Unlocking Scale: A Hybrid Architecture for Continental-Scale Energy Models
The Artelys, FICO, and NVIDIA collaboration focused on some of the most demanding optimisation challenges in energy modelling: unit commitment and power dispatch planning. These problems involve determining hourly electricity generation schedules, managing energy storage, and satisfying a wide range of technical and economic constraints—such as ramping limits, reserve margins, fuel usage, and transmission bottlenecks. Unit commitment problems (UCP), in particular, add combinatorial complexity through discrete variables like generator start-up and shutdown decisions, all modelled at a continental scale.
To address these challenges, the three partners designed a modular hybrid solver architecture that integrates FICO Xpress with NVIDIA cuOpt. As illustrated in Figure 1, energy models are first passed through a CPU-based presolve phase powered by Xpress, which simplifies and reduces the model size. From there, models are routed to either Xpress’s multithreaded CPU solvers or cuOpt’s GPU-accelerated engines for final solve.
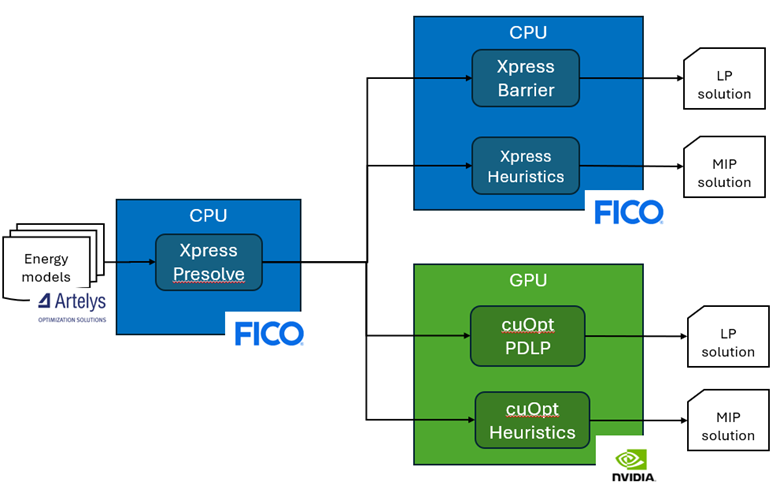
Figure 1. Hybrid solver architecture integrating FICO Xpress and NVIDIA cuOpt for large-scale energy optimisation.
This architecture is more than a design pattern—it’s a performance multiplier. As shown in Figure 2, Xpress preprocessing leads to a substantial reduction in the number of variables and constraints across several large-scale UCP instances. This reduction is critical not just for runtime gains but for enabling otherwise intractable models to be solved at all.
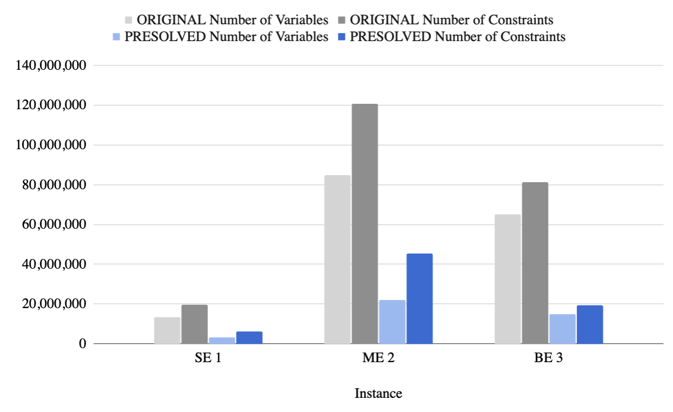
Figure 2. Unit commitment problem (UCP) instances’ scale before and after Xpress presolve.
These large-scale models push traditional solver boundaries, setting the stage for testing hybrid CPU-GPU architectures that combine the strengths of FICO Xpress CPU preprocessing with NVIDIA cuOpt GPU-accelerated solvers.
Benchmarking Performance: How Hybrid Solvers Unlock Speedups
To assess the real-world impact of CPU-GPU hybrid solvers, the team benchmarked a series of large-scale unit commitment problem (UCP) instances using the Artelys-developed models. The testing compared pure CPU-based barrier solves using FICO Xpress to hybrid pipelines where the problem is presolved with Xpress preprocessing on the CPU and solved on GPU using the cuOpt PDLP engine.
The results speak for themselves. As shown in Table 1, combining Xpress presolve with cuOpt’s GPU-accelerated solver achieves up to 20x speedups on the most complex instance BE 3. This reduces solve time from over 6 hours to just under 20 minutes.
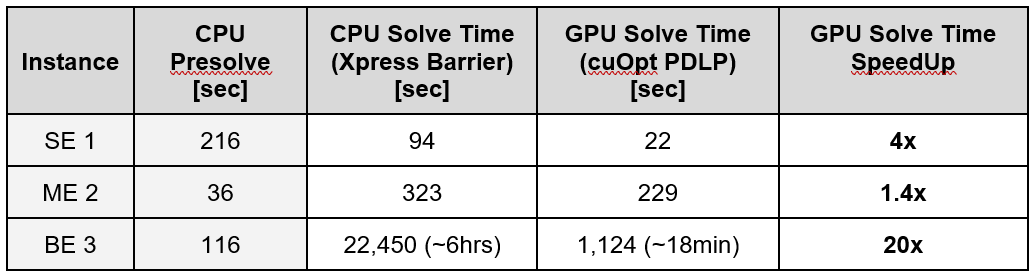
Table 1. Solve time comparisons across large presolved UCP instances.
Note: Test environments:
– FICO Xpress: AWS Graviton 3 CPU, 64 cores, 2.6 GHz, 128GB RAM
– NVIDIA cuOpt: NVIDIA B200 180GB HBM3e GPU, CUDA 12.8
For the largest model BE 3, the hybrid approach shaved hours off computation time. Attempts to use larger CPU-only setups with up to 192 cores delivered diminishing returns, revealing that performance becomes bottlenecked by memory bandwidth—a core strength of GPUs.
An important note: the Xpress barrier solver also benefits from advanced techniques such as LP folding, which is not yet available in cuOpt. This points out an interesting direction for future cooperation.
Solver performance continues to advance rapidly across both CPU and GPU platforms. Recent releases of FICO Xpress, for instance, incorporate state-of-the-art techniques such as LP folding, dualisation, and numerical preprocessing—enabling major performance gains, particularly for large, repetitive, or numerically challenging models. This tuning has resulted in solve time improvements for all three instances, but the biggest impact was on the ME 2 instance where a 100x reduction in solve time was achieved.
This illustrates a key insight from our study: there is no universally optimal solver strategy. The best approach varies by problem characteristics—including structure, problem size, numerical conditioning, available hardware, and system-level integration constraints.
While hybrid pipelines unlock major speedups, they also introduce trade-offs. For example, the cuOpt GPU-accelerated LP solver delivers exceptional performance on LP relaxations, but its default tolerances may impact solution precision in numerically sensitive scenarios. On the other hand, Xpress’s LP folding enhances speed on CPU, but can complicate crossover steps that are critical for effective MIP solving. Further note that the default primal and dual tolerances for Xpress Barrier are six digits (10e-6) and for NVIDIA cuOpt PDLP solver, four digits, which is more permissive.
In short, these results reinforce the need for a modular, adaptable solver architecture. By flexibly combining CPU and GPU technologies, users can tailor solver pipelines to match specific demands of each optimisation problem—balancing performance, robustness, and accuracy at scale.
Tackling MIP Complexity: Early Results and Future Directions
While linear programming tasks can benefit immediately from hybrid CPU-GPU acceleration, mixed-integer programming (MIP) introduces additional layers of complexity that remain more challenging to solve at scale.
Initial benchmarks highlight both progress and limitations. For the SE 1 instance, the hybrid pipeline—combining Xpress presolve with cuOpt GPU-based solver—was able to find a feasible solution within 15 minutes, outperforming default Xpress settings on the same problem. However, with targeted tuning—such as activating pre-root parallel heuristics, disabling crossover, and applying LP folding—Xpress alone also achieved a feasible solution in just 15 minutes, reaching an optimality gap below 2% under an hour.
More demanding problems show a similar pattern. On the ME 2 instance, Xpress’s parallel pre-root heuristics produced a feasible solution within two hours. In contrast, the BE 3 instance—by far the largest and most numerically challenging —remains unsolved, even after aggressive presolve. Its difficulty is attributed to extreme problem size and numerical instability, such as wide coefficient ranges across constraint matrices.
One promising research direction is exploring how to use non-basic interior point solutions (e.g., from cuOpt’s PDLP engine or Xpress’s Barrier solver) as effective starting points for MIP. Traditional MIP solvers rely on basic solutions to generate cutting planes and efficiently perform dual simplex reoptimisations. While interior-point methods can sometimes produce initial MIP solutions without crossover, advanced capabilities like strong cutting plane generation or warm starts still require basic representations.
That said, the high numerical accuracy of interior-point solvers may enable smoother transitions to basic form, minimising the cleanup needed post-crossover. Integrating this step into GPU-accelerated pipelines—particularly when working with the approximate solutions from cuOpt—remains a compelling opportunity for future collaboration among Artelys, FICO, and NVIDIA teams.
Ensuring Fairness: Transparency and Benchmarking Integrity
To make meaningful comparisons and draw credible conclusions, transparency has been a guiding principle throughout this benchmarking collaboration. Artelys, FICO, and NVIDIA are committed to a technically rigorous and reproducible approach, with the following context essential for interpreting the results accurately:
- Model origin and purpose: The models used in this study were independently developed by Artelys as part of its internal research, based on publicly available datasets and planning scenarios. They are not officially endorsed by transmission system operators (TSO), the European Commission, or any other governing body. Their purpose is to reflect realistic energy system planning challenges, not to serve as policy instruments.
- Inherent model complexity: Some structural features—such as unit-level symmetries common in unit commitment problems—introduce legitimate computational challenges. These features are natural consequences of realistic modelling and were not introduced to artificially increase difficulty. They reflect the actual complexity of the power systems being modelled.
- Hardware and solver configuration differences: The benchmarking results reflect performance on different compute architectures (CPU vs. GPU), with varying hardware specifications and solver configurations. As such, absolute timings should be interpreted with consideration for these differences, especially when comparing across platforms.
- Solver tolerances and stopping criteria: The solvers evaluated in this study differ in their default numerical tolerances, accuracy thresholds, and convergence criteria. These differences can impact both runtime and final solution quality and are an important factor in understanding performance variation.
Shaping What’s Next: Scalable Optimisation for Decarbonised Future
As energy systems grow in scale and complexity—driven by the ambitious decarbonisation goals, grid modernisation, and multi-vector integration—optimisation technologies must evolve to keep pace. This collaboration between FICO, NVIDIA, and Artelys demonstrates the transformative potential of CPU-GPU hybrid solver architectures: combining multithreaded CPU power for presolve with GPU-accelerated solving to overcome bottlenecks that previously limited model size, precision, and speed.
From feasibility breakthroughs to 20x speedups, these early results point to a new era of scalable, high-performance optimisation—one that’s not just feasible, but deployable across real-world energy, logistics, and mobility challenges.
The hybrid pipeline introduced here is particularly promising for next-generation planning problems such as capacity expansion and long-term energy transition pathway optimisation. These models involve making capital investment and operational decisions over multi-decade horizons, under uncertainty and with fine-grained time resolution. They must account for emissions, renewables, storage, flexible demand, and sector coupling across electricity, gas, heat, and mobility.
Traditionally, solving such massive linear programs required decomposition or approximations. Now, with hybrid solvers, we glimpse the possibility of solving them directly—with improved accuracy and reduced runtimes. This opens the door to more reliable and economically grounded pathways toward decarbonisation and energy resilience.
And this is only the beginning.
We invite energy planners, researchers, and system operators to explore how hybrid optimisation can accelerate innovation in their own environments.
Explore Artelys to learn how advanced modelling, optimisation, and decision support solutions are accelerating the energy transition.
Try FICO Xpress to experience the power of scalable, high-performance CPU solvers for enterprise decision making.
Visit NVIDIA cuOpt to experiment with open-source, GPU-accelerated solvers for linear, mixed-integer, and routing problems.
Join us in shaping the future of energy optimisation—where speed, scale, and sustainability converge.
Special thanks to the FICO and NVIDIA teams for their outstanding collaboration.

Artelys compared the compensation mechanisms available for hydropower across global electricity markets in collaboration with CEATI
— Artelys is proud to have issued a new report published by CEATI, providing a comprehensive benchmark of compensation mechanisms available to hydropower assets across electricity markets in North America, Europe, and beyond.

Artelys Crystal HPC: Our integrated, sovereign High-Performance Computing (HPC) managed platform for industries
— Organizations that run complex simulations, large-scale optimizations, or sensitive calculations face a threefold challenge: securing the computing power to match their ambitions, ensuring data sovereignty, and avoiding weeks of setup time before seeing initial results.

Artelys Expands to Switzerland with the Launch of Artelys Switzerland
— Artelys is pleased to announce the establishment of Artelys Switzerland, a new subsidiary based in Sion. This strategic expansion marks a significant step in the company’s continued international growth and reflects its commitment to better serving clients across the Swiss market and the broader DACH region.

Artelys delivers insights in European security of supply and the role of underground gas storage
Artelys delivers insights in European security of supply and the role of underground gas storage thanks to its advanced modelling capabilities.
subscribe to our newsletters
© ARTELYS • All rights reserved • Legal mentions