Scheduling¶
This chapter shows how to
define and setup the modeling objects
KTaskandKResource,formulate and solve scheduling problems using these objects,
access information from the modeling objects.
Tasks, resources and schedules¶
Scheduling and planning problems are concerned with determining a plan for the execution of a given set of tasks. The objective may be to generate a feasible schedule that satisfies the given constraints (such as sequence of tasks or limited resource availability) or to optimize a given criterion such as the makespan of the schedule. Artelys-Kalis defines several aggregate modeling objects to simplify the formulation of standard scheduling problems like tasks,resources and schedule objects. When working with these scheduling objects it is often sufficient to state the objects and their properties, such as task duration or resource use; the necessary constraint relations are set up automatically by Artelys-Kalis (referred to as implicit constraints). Before going further into the exploration of Artelys-Kalis scheduling capabilities, let’s first recall some basic concepts about scheduling problems and their modelisation that will be intensively used within this chapter.
Tasks¶
Tasks (processing operations, activities) are represented by the class KTask. This object contains three variables:
a start variable representing the starting time of the task
an end variable representing the ending time of the task
a duration variable representing the duration of the task
These three structural variables are linked by Artelys-Kalis with the following constraint: 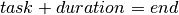 .
.
The starting time variable represents two specific parameters of the task:
* the Earliest Starting Time (EST represented by the start variable lower bound)
* and its Latest Starting Time (LST represented by the start variable upper bound).
The end variable represents two specific parameters of the task:
* the Earliest Completion Time (ECT represented by the end variable lower bound)
* and its Latest Completion Time (LCT represented by the end variable upper bound).
The duration variable represents two specific parameters of the task: * the minimum task duration (Dmin represented by the duration variable lower bound) * the maximum task duration (Dmax represented by the duration variable upper bound).
The picture below illustrates this:
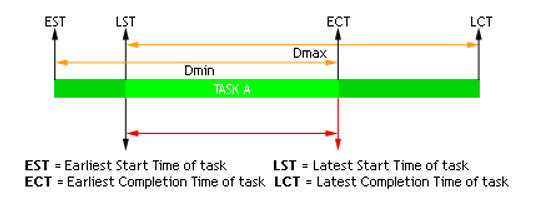
Fig. 8 Illustration of EST, ECT, LST and LCT paramters¶
Resources¶
Resources (machines, raw material etc.) can be of two different types:
Disjunctive when the resource can process only one task at a time (represented by the class
KunaryResource).Cumulative when the resource can process several tasks at the same time (represented by the class
KdiscreteResource).
Traditional examples of disjunctive resources are Jobshop problems, cumulative resources are heavily used for the Resource-Constrained Project Scheduling Problem (RCPSP). Note that a disjunctive resource is semantically equivalent to a cumulative resource with maximal capacity one and unit resource usage for each task using this resource but this equivalence does not hold in terms of constraint propagation.
The following schema shows an example with three tasks A,B and C executing on a disjunctive resource and on a cumulative resource with resource usage 3 for task A, 1 for task B and 1 for task C:
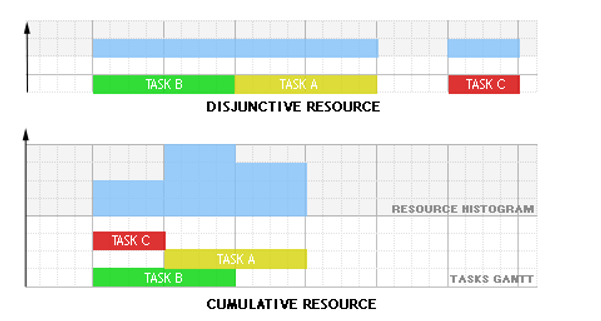
Fig. 9 Disjunctive and cumulative resources¶
Tasks may require, provide, consume and produce resources:
A task requires a resource if some amount of the resource capacity must be made available for the execution of the activity. The capacity is renewable which means that the required capacity is available after the end of the task.
A task provides a resource if some amount of the resource capacity is made available through the execution of the task. The capacity is renewable which means that the provided capacity is available only during the execution of the task.
A task consumes a resource if some amount of the resource capacity must be made available for the execution of the task and the capacity is non-renewable which means that the consumed capacity if no longer available at the end of the task.
A task produces a resource if some amount of the resource capacity is made available at the end of the task and the capacity is non-renewable which means that the produced capacity is definitively available after the task completion.
Schedule¶
Tasks and resources are gathered into a schedule. The method KSchedule::optimize() allows to optimize a schedule relatively to any objective variable (defined via the method KSchedule::setObjective() and implements advanced scheduling techniques specialized in makespan minimization. The creation of the schedule makespan can be automated by calling the KSchedule::getMakespan() method that ensures automatically its computation.
Artelys-Kalis Built-In Scheduler¶
In the following sections we show a number of examples using this mechanism:
The simplest case of a scheduling problem involves only tasks and precedence constraints between tasks (project scheduling problem in Section 11.2).
Tasks may be mutually exclusive, e.g. because they use the same unitary resource (disjunctive scheduling / sequencing problem in Section 11.3).
Resources may be usable by several tasks at a time, up to a given capacity limit (cumulative resources, see Section 11.4).
A different classification of resources is the distinction between renewable and nonrenewable resources (see Section 11.5).
Many extensions of the standard problems are possible, such as sequence-dependent setup time (see Section 11.6).
If the enumeration is started with the methods KSchedule::schedule() the solver will employ specialized search strategies suitable for the corresponding (scheduling) problem type. However, it is also possible to employ parameterized search strategies or to define user search strategies for scheduling objects in this case the standard optimization functions KSolver::minimize() or KSolver::maximize() need to be used (see Section 11.7).
The properties of scheduling objects (such as start time or duration of tasks) can be accessed and employed, for instance, in the definition of constraints, thus giving the user the possibility to extend the predefined standard problems with other types of constraints. For even greater flexibility Artelys-Kalis also enables the user to formulate his scheduling problems without the aggregate modeling objects, using dedicated global constraints on decision variables of type KIntVar. Most examples in this chapter are therefore given with two different implementations, one using the scheduling objects and another without these objects.
Precedences¶
Probably the most basic type of a scheduling problem is to plan a set of tasks that are linked by precedence constraints. The problem described in this section is taken from Section 7.1 Construction of a stadium of the book Applications of optimization with Xpress-MP.
A construction company has been awarded a contract to construct a stadium and wishes to complete it within the shortest possible time. Figure Fig. 10 lists the major tasks and their durations in weeks. Some tasks can only start after the completion of certain other tasks, equally indicated in the table.
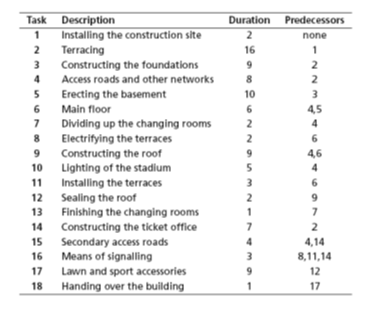
Fig. 10 Data for stadium construction¶
Model formulation¶
This problem is a classical project scheduling problem. We add a fictitious task with 0 duration that corresponds to the end of the project.
We thus consider the set of tasks 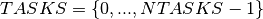 where
where 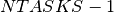 is the fictitious end task. Every construction task
is the fictitious end task. Every construction task 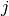 (
(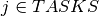 ) is represented by a
) is represented by a KTask object 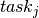 with variable start time
with variable start time 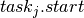 and a duration fixed to the given value
and a duration fixed to the given value 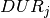 . The precedences between tasks are represented by a precedence graph with arcs (
. The precedences between tasks are represented by a precedence graph with arcs (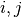 ) symbolizing that task
) symbolizing that task 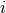 precedes task . The objective is to minimize the completion time of the project, that is the start time of the last, fictitious task
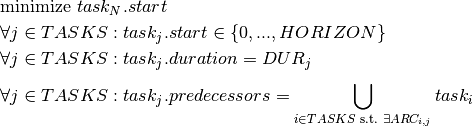
precedes task . The objective is to minimize the completion time of the project, that is the start time of the last, fictitious task 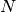 . We thus obtain the following model where an upper bound
. We thus obtain the following model where an upper bound 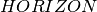 on the start times is given by the sum of all task durations:
on the start times is given by the sum of all task durations:
Implementation¶
The following model shows the implementation of this problem with Artelys-Kalis. Since there are no side-constraints, the earliest possible completion time of the schedule is the earliest start of the fictitious task . To trigger the propagation of task-related constraints we simply call the method KProblem::propagate() as usual. At this point, constraining the start of the fictitious end task to its lower bound reduces all task start times to their feasible intervals through the effect of constraint propagation. The start times of tasks on the critical path are fixed to a single value. The call to KSchedule::optimize() serves for instantiating all variables to their lower bounds.
// Number of tasks
int NTASKS = 19;
// Duration of tasks
int DUR[] = {2 ,16 , 9 , 8, 10, 6 , 2 , 2 , 9 , 5 , 3 , 2 , 1 , 7 , 4 , 3 , 9 , 1 , 0};
// Time horizon
int HORIZON;
// Tasks to be planned
KTaskArray task;
// best upper bound
int bestend;
// index variable
int indexTask;
// computing maximal time horizon;
HORIZON = 0;
for (indexTask = 0;indexTask < NTASKS; indexTask++) {
HORIZON += DUR[indexTask];
}
// Creation of the problem in this session
KProblem problem(session,"B-1 Stadium construction");
// Creation of the schedule object with time horizon (0..HORIZON)
KSchedule schedule(problem,"B-1 Stadium construction schedule",0,HORIZON);
char name[80];
// building each task with fixed duration
for (indexTask = 0;indexTask < NTASKS; indexTask++) {
sprintf(name,"T%i",indexTask);
task += * (new KTask(schedule,name,DUR[indexTask]) ) ;
}
// setting the predecessors of each task
task[1].startsAfter(task[0]);
task[2].startsAfter(task[1]);
task[3].startsAfter(task[1]);
task[13].startsAfter(task[1]);
task[4].startsAfter(task[2]);
task[5].startsAfter(task[3]);
task[6].startsAfter(task[3]);
task[8].startsAfter(task[3]);
task[9].startsAfter(task[3]);
task[14].startsAfter(task[3]);
task[5].startsAfter(task[4]);
task[7].startsAfter(task[5]);
task[8].startsAfter(task[5]);
task[10].startsAfter(task[5]);
task[12].startsAfter(task[6]);
task[15].startsAfter(task[7]);
task[11].startsAfter(task[8]);
task[18].startsAfter(task[9]);
task[15].startsAfter(task[10]);
task[16].startsAfter(task[11]);
task[18].startsAfter(task[12]);
task[14].startsAfter(task[13]);
task[15].startsAfter(task[13]);
task[18].startsAfter(task[14]);
task[18].startsAfter(task[15]);
task[17].startsAfter(task[16]);
task[18].startsAfter(task[17]);
// propagating problem
if (problem.propagate()) {
printf("Problem is infeasible\n");
exit(1);
}
// Since there are no side-constraints, the earliest possible completion
// time is the earliest start of the fictitious task N
bestend = task[NTASKS-1].getStartDateVar()->getInf();
task[NTASKS-1].getStartDateVar()->setSup(bestend);
printf("Earliest possible completion time: %i\n", bestend);
// For tasks on the critical path the start/completion times have been fixed
// by setting the bound on the last task. For all other tasks the range of
// possible start/completion times gets displayed.
for (indexTask = 0;indexTask < NTASKS; indexTask++) {
printf("%i:",indexTask);
task[indexTask].getStartDateVar()->print();
printf("\n");
}
// Complete enumeration: schedule every task at the earliest possible date
int result = schedule.optimize();
// solution printing
problem.getSolution().print();
from kalis import *
### Data
# Number of tasks
nb_tasks = 19
# Duration of tasks
durations = [2, 16, 9, 8, 10, 6, 2, 2, 9, 5, 3, 2, 1, 7, 4, 3, 9, 1, 0]
# Time horizon
horizon = sum(durations)
# Setting the predecessors of each task
precedences = [(1, 0), (2, 1), (3, 1), (13, 1), (4, 2), (5, 3), (6, 3), (8, 3), (9, 3),
(14, 3), (5, 4), (7, 5), (8, 5), (10, 5), (12, 6), (15, 7), (11, 8), (18, 9),
(15, 10), (16, 11), (18, 12), (14, 13), (15, 13), (18, 14), (18, 15), (17, 16),
(18, 17)]
### Problem creation
session = KSession()
# Creation of the problem in this session
problem = KProblem(session, "B-1 Stadium construction")
# Creation of the schedule object with time horizon (0..horizon)
schedule = KSchedule(problem, "B-1 Stadium construction schedule", 0, horizon)
### Variables creation
# Tasks to be planned
tasks = KTaskArray()
for task_index in range(nb_tasks):
tasks += KTask(schedule, "T%d" % task_index, durations[task_index])
# Setting the predecessors of each task
for (i, j) in precedences:
tasks[i].startsAfter(tasks[j])
### Solving phase
# propagating problem
if problem.propagate():
print("Problem is infeasible")
sys.exit(1)
# Since there are no side-constraints, the earliest possible completion time is the earliest
# start of the fictitious task N
bestend = tasks[nb_tasks - 1].getStartDateVar().getInf()
tasks[nb_tasks - 1].getStartDateVar().setSup(int(bestend))
print("Earliest possible completion time: %d" % bestend)
# For tasks on the critical path the start/completion times have been fixed
# by setting the bound on the last task. For all other tasks the range of
# possible start/completion times gets displayed.
for task_index in range(nb_tasks):
tasks[task_index].getStartDateVar().display()
print("")
# Complete enumeration: schedule every task at the earliest possible date
result = schedule.optimize()
# solution printing
problem.getSolution().display()
// Number of tasks
int NTASKS = 19;
// Duration of tasks
int DUR[] = {2,16, 9, 8, 10, 6, 2, 2, 9, 5, 3, 2, 1, 7, 4, 3, 9, 1, 0};
// Time horizon
int HORIZON;
// Tasks to be planned
KTaskArray task = new KTaskArray();
// best upper bound
int bestend;
// index variable
int indexTask;
// computing maximal time horizon;
HORIZON = 0;
for (indexTask = 0; indexTask < NTASKS; indexTask++)
{
HORIZON += DUR[indexTask];
}
// Creation of the problem in this session
KProblem problem = new KProblem(session, "B-1 Stadium construction");
// Creation of the schedule object with time horizon (0..HORIZON)
KSchedule schedule = new KSchedule(problem, "B-1 Stadium construction schedule", 0, HORIZON);
// building each tasks with fixed duration
for (indexTask = 0; indexTask < NTASKS; indexTask++)
{
task.add(new KTask(schedule, "T" + indexTask, DUR[indexTask]) ) ;
}
// setting the predecessors of each tasks
task.getElt(1).startsAfter(task.getElt(0));
task.getElt(2).startsAfter(task.getElt(1));
task.getElt(3).startsAfter(task.getElt(1));
task.getElt(13).startsAfter(task.getElt(1));
task.getElt(4).startsAfter(task.getElt(2));
task.getElt(5).startsAfter(task.getElt(3));
task.getElt(6).startsAfter(task.getElt(3));
task.getElt(8).startsAfter(task.getElt(3));
task.getElt(9).startsAfter(task.getElt(3));
task.getElt(14).startsAfter(task.getElt(3));
task.getElt(5).startsAfter(task.getElt(4));
task.getElt(7).startsAfter(task.getElt(5));
task.getElt(8).startsAfter(task.getElt(5));
task.getElt(10).startsAfter(task.getElt(5));
task.getElt(12).startsAfter(task.getElt(6));
task.getElt(15).startsAfter(task.getElt(7));
task.getElt(11).startsAfter(task.getElt(8));
task.getElt(18).startsAfter(task.getElt(9));
task.getElt(15).startsAfter(task.getElt(10));
task.getElt(16).startsAfter(task.getElt(11));
task.getElt(18).startsAfter(task.getElt(12));
task.getElt(14).startsAfter(task.getElt(13));
task.getElt(15).startsAfter(task.getElt(13));
task.getElt(18).startsAfter(task.getElt(14));
task.getElt(18).startsAfter(task.getElt(15));
task.getElt(17).startsAfter(task.getElt(16));
task.getElt(18).startsAfter(task.getElt(17));
// propagating problem
if (problem.propagate())
{
System.out.println("Problem is infeasible");
exit(1);
}
// Since there are no side-constraints, the earliest possible completion
// time is the earliest start of the fictitiuous task N
bestend = (int) task.getElt(NTASKS - 1).getStartDateVar().getInf();
task.getElt(NTASKS-1).getStartDateVar().setSup(bestend);
System.out.println("Earliest possible completion time: " + bestend);
// For tasks on the critical path the start/completion times have been fixed
// by setting the bound on the last task. For all other tasks the range of
// possible start/completion times gets displayed.
for (indexTask = 0; indexTask < NTASKS; indexTask++)
{
System.out.println(indexTask + ":" + task.getElt(indexTask).getStartDateVar().getValue());
}
// Complete enumeration: schedule every task at the earliest possible date
schedule.optimize();
// solution printing
problem.getSolution().print();
Results¶
The earliest completion time of the stadium construction is 64 weeks. Here is a graphical representation of the solution:
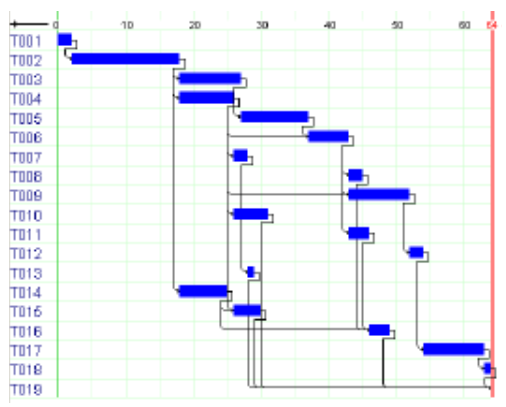
Fig. 11 Results of Stadium Construction example¶
Alternative formulation without scheduling objects¶
As for the previous formulation, we work with a set of tasks 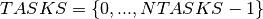 where is the fictitious end task. For every task we introduce a decision variable
where is the fictitious end task. For every task we introduce a decision variable 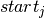 to denote its start time. With the duration of task , the precedence relation task i precedes task j is stated by the constraint :
to denote its start time. With the duration of task , the precedence relation task i precedes task j is stated by the constraint : 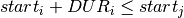
We therefore obtain the following model for our project scheduling problem:
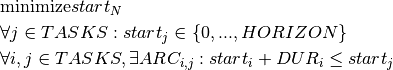
The corresponding model is printed in full below:
// Number of tasks
int NTASKS = 19;
// Duration of tasks
int DUR[] = {2 ,16 , 9 , 8, 10, 6 , 2 , 2 , 9 , 5 , 3 , 2 , 1 , 7 , 4 , 3 , 9 , 1 , 0};
// Time horizon
int HORIZON;
// Start dates of tasks to be planned
KIntVarArray starts;
// best upper bound
int bestend;
// index variable
int indexTask;
// computing maximal time horizon;
HORIZON = 0;
for (indexTask = 0;indexTask < NTASKS; indexTask++) {
HORIZON += DUR[indexTask];
}
// Creation of the problem in this session
KProblem problem(session,"B-1 Stadium construction - Alt");
char name[80];
// building each tasks with fixed time horizon (0..HORIZON)
for (indexTask = 0;indexTask < NTASKS; indexTask++) {
sprintf(name,"T%i",indexTask);
starts += * (new KIntVar(problem,name,0,HORIZON) );
}
// setting the predecessors of each tasks
problem.post( starts[1] >= starts[0] + DUR[0] );
problem.post( starts[2] >= starts[1] + DUR[1] );
problem.post( starts[3] >= starts[1] + DUR[1] );
problem.post( starts[13] >= starts[1] + DUR[1] );
problem.post( starts[4] >= starts[2] + DUR[2] );
problem.post( starts[5] >= starts[3] + DUR[3] );
problem.post( starts[6] >= starts[3] + DUR[3] );
problem.post( starts[8] >= starts[3] + DUR[3] );
problem.post( starts[9] >= starts[3] + DUR[3] );
problem.post( starts[14] >= starts[3] + DUR[3] );
problem.post( starts[5] >= starts[4] + DUR[4] );
problem.post( starts[7] >= starts[5] + DUR[5] );
problem.post( starts[8] >= starts[5] + DUR[5] );
problem.post( starts[10] >= starts[5] + DUR[5] );
problem.post( starts[12] >= starts[6] + DUR[6] );
problem.post( starts[15] >= starts[7] + DUR[7] );
problem.post( starts[11] >= starts[8] + DUR[8] );
problem.post( starts[18] >= starts[9] + DUR[9] );
problem.post( starts[15] >= starts[10] + DUR[10] );
problem.post( starts[16] >= starts[11] + DUR[11] );
problem.post( starts[18] >= starts[12] + DUR[12] );
problem.post( starts[14] >= starts[13] + DUR[13] );
problem.post( starts[15] >= starts[13] + DUR[13] );
problem.post( starts[18] >= starts[14] + DUR[14] );
problem.post( starts[18] >= starts[15] + DUR[15] );
problem.post( starts[17] >= starts[16] + DUR[16] );
problem.post( starts[18] >= starts[17] + DUR[17] );
// propagating problem
if (problem.propagate()) {
printf("Problem is infeasible\n");
exit(1);
}
// Since there are no side-constraints, the earliest possible completion
// time is the earliest start of the fictitious task N
bestend = starts[NTASKS-1].getInf();
starts[NTASKS-1].setSup(bestend);
printf("Earliest possible completion time: %i\n", bestend);
// For tasks on the critical path the start/completion times have been fixed
// by setting the bound on the last task. For all other tasks the range of
// possible start/completion times gets displayed.
for (indexTask = 0;indexTask < NTASKS; indexTask++) {
printf("%i:",indexTask);
starts[indexTask].print();
printf("\n");
}
problem.setObjective(starts[18]);
problem.setSense(KProblem::Minimize);
KSolver solver(problem);
// Complete enumeration: schedule every task at the earliest possible date
int result = solver.optimize();
// solution printing
problem.getSolution().print();
from kalis import *
### Data
# Number of tasks
nb_tasks = 19
# Duration of tasks
durations = [2, 16, 9, 8, 10, 6, 2, 2, 9, 5, 3, 2, 1, 7, 4, 3, 9, 1, 0]
# Time horizon
horizon = sum(durations)
# Setting the predecessors of each task
precedences = [(1, 0), (2, 1), (3, 1), (13, 1), (4, 2), (5, 3), (6, 3), (8, 3), (9, 3),
(14, 3), (5, 4), (7, 5), (8, 5), (10, 5), (12, 6), (15, 7), (11, 8), (18, 9),
(15, 10), (16, 11), (18, 12), (14, 13), (15, 13), (18, 14), (18, 15), (17, 16),
(18, 17)]
### Problem creation
session = KSession()
# Creation of the problem in this session
problem = KProblem(session, "B-1 Stadium construction - Alt")
### Variables creation
# Tasks to be planned
starts = KIntVarArray()
for task_index in range(nb_tasks):
starts += KIntVar(problem, "T%d" % task_index, 0, horizon)
for (i, j) in precedences:
problem.post(starts[i] >= starts[j] + durations[j])
### Solving phase
# propagating problem
if problem.propagate():
print("Problem is infeasible")
sys.exit(1)
# Since there are no side-constraints, the earliest possible completion time is the earliest
# start of the fictitious task N
bestend = starts[nb_tasks - 1].getInf()
starts[nb_tasks - 1].setSup(int(bestend))
print("Earliest possible completion time: %d" % bestend)
# For tasks on the critical path the start/completion times have been fixed
# by setting the bound on the last task. For all other tasks the range of
# possible start/completion times gets displayed.
for task_index in range(nb_tasks):
starts[task_index].display()
print("")
# Set objective
problem.setObjective(starts[nb_tasks - 1])
problem.setSense(KProblem.Minimize)
solver = KSolver(problem)
result = solver.optimize()
# solution printing
problem.getSolution().display()
// Number of tasks
int NTASKS = 19;
// Duration of tasks
int DUR[] = {2,16, 9, 8, 10, 6, 2, 2, 9, 5, 3, 2, 1, 7, 4, 3, 9, 1, 0};
// Time horizon
int HORIZON;
// Start dates of tasks to be planned
KIntVarArray starts = new KIntVarArray();
// best upper bound
int bestend;
// index variable
int indexTask;
// computing maximal time horizon;
HORIZON = 0;
for (indexTask = 0; indexTask < NTASKS; indexTask++)
{
HORIZON += DUR[indexTask];
}
// Creation of the problem in this session
KProblem problem = new KProblem(session, "B-1 Stadium construction - Alt");
// building each tasks with fixed time horizon (0..HORIZON)
for (indexTask = 0; indexTask < NTASKS; indexTask++)
{
starts.add(new KIntVar(problem, "T" + indexTask + ".start", 0, HORIZON) );
}
// setting the predecessors of each tasks
problem.post(new KGreaterOrEqualXyc(starts.getElt(1), starts.getElt(0), DUR[0] ));
problem.post(new KGreaterOrEqualXyc(starts.getElt(2),starts.getElt(1), DUR[1] ));
problem.post(new KGreaterOrEqualXyc(starts.getElt(3), starts.getElt(1), DUR[1] ));
problem.post(new KGreaterOrEqualXyc(starts.getElt(13), starts.getElt(1), DUR[1] ));
problem.post(new KGreaterOrEqualXyc(starts.getElt(4), starts.getElt(2), DUR[2] ));
problem.post(new KGreaterOrEqualXyc(starts.getElt(5), starts.getElt(3), DUR[3] ));
problem.post(new KGreaterOrEqualXyc(starts.getElt(6), starts.getElt(3), DUR[3] ));
problem.post(new KGreaterOrEqualXyc(starts.getElt(8), starts.getElt(3), DUR[3] ));
problem.post(new KGreaterOrEqualXyc(starts.getElt(9), starts.getElt(3), DUR[3] ));
problem.post(new KGreaterOrEqualXyc(starts.getElt(14), starts.getElt(3), DUR[3] ));
problem.post(new KGreaterOrEqualXyc(starts.getElt(5), starts.getElt(4), DUR[4] ));
problem.post(new KGreaterOrEqualXyc(starts.getElt(7), starts.getElt(5), DUR[5] ));
problem.post(new KGreaterOrEqualXyc(starts.getElt(8), starts.getElt(5), DUR[5] ));
problem.post(new KGreaterOrEqualXyc(starts.getElt(10), starts.getElt(5), DUR[5] ));
problem.post(new KGreaterOrEqualXyc(starts.getElt(12), starts.getElt(6), DUR[6] ));
problem.post(new KGreaterOrEqualXyc(starts.getElt(15), starts.getElt(7), DUR[7] ));
problem.post(new KGreaterOrEqualXyc(starts.getElt(11), starts.getElt(8), DUR[8] ));
problem.post(new KGreaterOrEqualXyc(starts.getElt(18), starts.getElt(9), DUR[9] ));
problem.post(new KGreaterOrEqualXyc(starts.getElt(15), starts.getElt(10), DUR[10] ));
problem.post(new KGreaterOrEqualXyc(starts.getElt(16), starts.getElt(11), DUR[11] ));
problem.post(new KGreaterOrEqualXyc(starts.getElt(18), starts.getElt(12), DUR[12] ));
problem.post(new KGreaterOrEqualXyc(starts.getElt(14), starts.getElt(13), DUR[13] ));
problem.post(new KGreaterOrEqualXyc(starts.getElt(15), starts.getElt(13), DUR[13] ));
problem.post(new KGreaterOrEqualXyc(starts.getElt(18), starts.getElt(14), DUR[14] ));
problem.post(new KGreaterOrEqualXyc(starts.getElt(18), starts.getElt(15), DUR[15] ));
problem.post(new KGreaterOrEqualXyc(starts.getElt(17), starts.getElt(16), DUR[16] ));
problem.post(new KGreaterOrEqualXyc(starts.getElt(18), starts.getElt(17), DUR[17] ));
// propagating problem
if (problem.propagate())
{
System.out.println("Problem is infeasible");
exit(1);
}
// Since there are no side-constraints, the earliest possible completion
// time is the earliest start of the fictitiuous task N
bestend = (int) starts.getElt(NTASKS - 1).getInf();
starts.getElt(NTASKS-1).setSup(bestend);
System.out.println("Earliest possible completion time: " + bestend);
// For tasks on the critical path the start/completion times have been fixed
// by setting the bound on the last task. For all other tasks the range of
// possible start/completion times gets displayed.
for (indexTask = 0; indexTask < NTASKS; indexTask++)
{
System.out.println(indexTask + ":" + starts.getElt(indexTask).getValue());
}
problem.setObjective(starts.getElt(18));
problem.setSense(KProblem.Sense.Minimize);
KSolver solver = new KSolver(problem);
// Complete enumeration: schedule every task at the earliest possible date
solver.optimize();
// solution printing
problem.getSolution().print();
Disjunctive scheduling: unary resources¶
The problem of sequencing jobs on a single machine described in Section 11.3 may be represented as a disjunctive scheduling problem using the KTask and KResource modeling objects. The reader is reminded that the problem is to schedule the processing of a set of non-preemptive tasks (or jobs) on a single machine. For every task its release date, duration, and due date are given. The problem is to be solved with three different objectives, mimizing the makespan, the average completion time, or the total tardiness.
Model formulation¶
The major part of the model formulation consists of the definition of the scheduling objects tasks and resources.
Every job (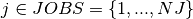 ) is represented by a task object , with a start time in
) is represented by a task object , with a start time in 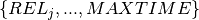 (where
(where 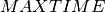 is a sufficiently large value, such as the sum of all release dates and all durations, and
is a sufficiently large value, such as the sum of all release dates and all durations, and 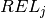 the release date of job ) and the task duration
the release date of job ) and the task duration 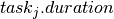 fixed to the given processing time . All jobs use the same resource
fixed to the given processing time . All jobs use the same resource 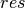 of unitary capacity. This means that at most one job may be processed at any one time, we thus implicitly state the disjunctions between the jobs. Another implicit constraint established by the task objects is the relation between the start, duration, and completion time of a job .
of unitary capacity. This means that at most one job may be processed at any one time, we thus implicitly state the disjunctions between the jobs. Another implicit constraint established by the task objects is the relation between the start, duration, and completion time of a job .
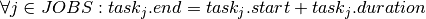
Objective 1: The first objective is to minimize the makespan (completion time of the schedule) or, equivalently, to minimize the completion time finish of the last job. The complete model is then given by the following (where is a sufficiently large value, such as the sum of all release dates and all durations):

Objective 2: The formulation of the second objective (minimizing the average processing time or, equivalently, minimizing the sum of the job completion times) remains unchanged from the first model we introduce an additional variable 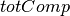 representing the sum of the completion times of all jobs.
representing the sum of the completion times of all jobs.
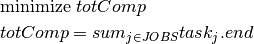
Objective 3: To formulate the objective of minimizing the total tardiness, we introduce new variables 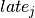 to measure the amount of time that a job finishes after its due date. The value of these variables corresponds to the difference between the completion time of a job and its due date
to measure the amount of time that a job finishes after its due date. The value of these variables corresponds to the difference between the completion time of a job and its due date 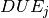 . If the job finishes before its due date, the value must be zero. The objective now is to minimize the sum of these tardiness variables:
. If the job finishes before its due date, the value must be zero. The objective now is to minimize the sum of these tardiness variables:
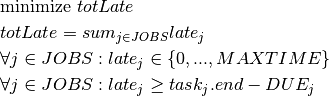
The following implementation with Artelys-Kalis shows how to set up the necessary task and resource modeling objects. The resource is of the type KUnaryResource meaning that it processes at most one task at a time. For the tasks we use the constructor of KTask with the following signature:
KTask(KSchedule &s,const char * name,int duration,KResource & r);
KTask(schedule, name, duration, resource)
# 'schedule' type: KSchedule
# 'name' type: str
# 'duration' type: int
# 'resource' type: KResource
KTask(KSchedule s, name, duration, new KResource());
The last parameter indicates that the task use the resource r with unitary ressource requirement. The latter exists in several versions for different combinations of arguments (task attributes) the reader is referred to the Artelys-Kalis Reference Manual for further detail.
// Number of tasks
int NTASKS = 7;
// Release date of tasks
int REL[] = { 2, 5, 4, 0, 0, 8, 9};
// Duration of tasks
int DUR[] = { 5, 6, 8, 4, 2, 4, 2};
// Due date of tasks
int DUE[] = {10, 21, 15, 10, 5, 15, 22};
// Time horizon
int MAXTIME;
// Tasks to be planned
KTaskArray task;
// best upper bound
int bestend;
// index variable
int indexTask;
// computing maximal time horizon;
int SUMDUR = 0;
for (indexTask = 0;indexTask < NTASKS; indexTask++) {
SUMDUR += DUR[indexTask];
}
MAXTIME = 0;
for (indexTask = 0;indexTask < NTASKS; indexTask++) {
if (REL[indexTask] + DUR[indexTask] > MAXTIME) {
MAXTIME = REL[indexTask] + SUMDUR;
}
}
// Creation of the problem in this session
KProblem problem(session,"B-4 Sequencing");
// Creation of the schedule object with time horizon (0..MAXTIME)
KSchedule schedule(problem,"B-4 Sequencing schedule",0,100);
// Resource (machine)
KUnaryResource cpresource(schedule,"machine");
char name[80];
// building each tasks with fixed duration
for (indexTask = 0;indexTask < NTASKS; indexTask++) {
sprintf(name,"T%i",indexTask);
task += * (new KTask(schedule,name,DUR[indexTask],cpresource) ) ;
task[indexTask].getStartDateVar()->setInf(REL[indexTask]);
}
// propagating problem
if (problem.propagate()) {
printf("Problem is infeasible\n");
exit(1);
}
// **********************
// Objective 1: Makespan
// **********************
int result = schedule.optimize();
// solution printing
printf("Completion time: %i\n",problem.getSolution().getValue(*schedule.getMakeSpan()));
printf("Rel\t");
for (indexTask = 0;indexTask < NTASKS; indexTask++) {
printf("%i\t",REL[indexTask]);
}
printf("\nDur\t");
for (indexTask = 0;indexTask < NTASKS; indexTask++) {
printf("%i\t",DUR[indexTask]);
}
printf("\nStart\t");
for (indexTask = 0;indexTask < NTASKS; indexTask++) {
printf("%i\t",problem.getSolution().getValue(*task[indexTask].getStartDateVar()));
}
printf("\nEnd\t");
for (indexTask = 0;indexTask < NTASKS; indexTask++) {
printf("%i\t",problem.getSolution().getValue(*task[indexTask].getEndDateVar()));
}
printf("\nDue\t");
for (indexTask = 0;indexTask < NTASKS; indexTask++) {
printf("%i\t",DUE[indexTask]);
}
printf("\n");
// ***************************************
// Objective 2: Average completion time:
// ***************************************
KLinTerm totalCompletionTerm;
for (indexTask = 0;indexTask < NTASKS; indexTask++) {
totalCompletionTerm = totalCompletionTerm + *task[indexTask].getEndDateVar();
}
KIntVar averageCompletion(problem,"average completion",0,1000);
problem.post(averageCompletion == totalCompletionTerm);
schedule.setObjective(averageCompletion);
result = schedule.optimize();
// solution printing
printf("Completion time: %i\n",problem.getSolution().getValue(*schedule.getMakeSpan()));
printf("average: %i\n",problem.getSolution().getValue(averageCompletion));
printf("Rel\t");
for (indexTask = 0;indexTask < NTASKS; indexTask++) {
printf("%i\t",REL[indexTask]);
}
printf("\nDur\t");
for (indexTask = 0;indexTask < NTASKS; indexTask++) {
printf("%i\t",DUR[indexTask]);
}
printf("\nStart\t");
for (indexTask = 0;indexTask < NTASKS; indexTask++) {
printf("%i\t",problem.getSolution().getValue(*task[indexTask].getStartDateVar()));
}
printf("\nEnd\t");
for (indexTask = 0;indexTask < NTASKS; indexTask++) {
printf("%i\t",problem.getSolution().getValue(*task[indexTask].getEndDateVar()));
}
printf("\nDue\t");
for (indexTask = 0;indexTask < NTASKS; indexTask++) {
printf("%i\t",DUE[indexTask]);
}
printf("\n");
// *****************************
// Objective 3: total lateness:
// *****************************
KIntVarArray late;
KLinTerm totLatTerm;
// building each tasks with fixed time horizon (0..HORIZON)
for (indexTask = 0;indexTask < NTASKS; indexTask++) {
sprintf(name,"late(%i)",indexTask);
late += * (new KIntVar(problem,name,0,MAXTIME) );
problem.post(late[indexTask] >= (*task[indexTask].getEndDateVar()) - DUE[indexTask]);
totLatTerm = totLatTerm + late[indexTask];
}
KIntVar totLate(problem,"total lateness",0,1000);
problem.post(totLate == totLatTerm);
schedule.setObjective(totLate);
result = schedule.optimize();
// solution printing
printf("Completion time: %i\n",problem.getSolution().getValue(*schedule.getMakeSpan()));
printf("average: %i\n",problem.getSolution().getValue(averageCompletion));
printf("Tardiness: %i\n",problem.getSolution().getValue(totLate));
printf("Rel\t");
for (indexTask = 0;indexTask < NTASKS; indexTask++) {
printf("%i\t",REL[indexTask]);
}
printf("\nDur\t");
for (indexTask = 0;indexTask < NTASKS; indexTask++) {
printf("%i\t",DUR[indexTask]);
}
printf("\nStart\t");
for (indexTask = 0;indexTask < NTASKS; indexTask++) {
printf("%i\t",problem.getSolution().getValue(*task[indexTask].getStartDateVar()));
}
printf("\nEnd\t");
for (indexTask = 0;indexTask < NTASKS; indexTask++) {
printf("%i\t",problem.getSolution().getValue(*task[indexTask].getEndDateVar()));
}
printf("\nDue\t");
for (indexTask = 0;indexTask < NTASKS; indexTask++) {
printf("%i\t",DUE[indexTask]);
}
printf("\nLate\t");
for (indexTask = 0;indexTask < NTASKS; indexTask++) {
printf("%i\t",problem.getSolution().getValue(late[indexTask]));
}
printf("\n");
from kalis import *
### Data creation
nb_tasks = 7
release_dates = [2, 5, 4, 0, 0, 8, 9]
durations = [5, 6, 8, 4, 2, 4, 2]
due_dates = [10, 21, 15, 10, 5, 15, 22]
### Creation of the problem
# Creation of the Kalis session
session = KSession()
# Creation of the problem in this session
problem = KProblem(session, "B-4 Sequencing")
# Creation of the schedule object with time horizon (0..MAXTIME)
durations_sum = sum(durations)
max_time = max(durations_sum + release_dates[j] - durations[j] for j in range(nb_tasks))
schedule = KSchedule(problem, "B-4 Sequencing schedule", 0, max_time)
# Resource (machine)
cpresource = KUnaryResource(schedule, "machine")
# Tasks positions
tasks = KTaskArray()
for task_index in range(nb_tasks):
tasks += KTask(schedule, "T%d" % task_index, durations[task_index], cpresource)
tasks[task_index].getStartDateVar().setInf(release_dates[task_index])
### Solve the problem
# First propagation of the problem
if problem.propagate():
print("Problem is infeasible")
sys.exit(1)
### Objective 1 : minimize the makespan
result = schedule.optimize()
# solution printing
def printSequencingSolution(solution, schedule):
print("Completion time: %d" % solution.getValue(schedule.getMakeSpan()))
print("Release dates: ", end='\t')
for task_index in range(nb_tasks):
print(release_dates[task_index], end="\t")
print("\nDurations: ", end='\t')
for task_index in range(nb_tasks):
print(durations[task_index], end="\t")
print("\nStart dates: ", end='\t')
for task_index in range(nb_tasks):
print(solution.getValue(tasks[task_index].getStartDateVar()), end="\t")
print("\nEnd dates: ", end='\t')
for task_index in range(nb_tasks):
print(solution.getValue(tasks[task_index].getEndDateVar()), end="\t")
print("\nDue dates: ", end='\t')
for task_index in range(nb_tasks):
print(due_dates[task_index], end="\t")
print("")
if result:
solution = problem.getSolution()
printSequencingSolution(solution, schedule)
### Objective 2: minimize the average completion time
jobs_completions_sum = 0
for task_index in range(nb_tasks):
jobs_completions_sum += tasks[task_index].getEndDateVar()
average_completion = KIntVar(problem, "average completion", 0, 1000)
problem.post(average_completion == jobs_completions_sum)
schedule.setObjective(average_completion)
result = schedule.optimize()
if result:
solution = problem.getSolution()
print("Average completion time: %f" % (solution.getValue(average_completion) / nb_tasks))
printSequencingSolution(solution, schedule)
### Objective 3: minimize the total lateness
# Declare lateness of each job as a variable
jobs_lateness = KIntVarArray()
lateness_sum = 0
for task_index in range(nb_tasks):
jobs_lateness += KIntVar(problem, "late(%d)" % task_index, 0, max_time)
problem.post(jobs_lateness[task_index] >= (tasks[task_index].getEndDateVar() - due_dates[task_index]))
lateness_sum += jobs_lateness[task_index]
total_lateness = KIntVar(problem, "total lateness", 0, nb_tasks * max_time)
problem.post(total_lateness == lateness_sum)
schedule.setObjective(total_lateness)
result = schedule.optimize()
if result:
solution = problem.getSolution()
print("Average completion time: %f" % (solution.getValue(average_completion) / nb_tasks))
print("Tardiness: %d" % solution.getValue(total_lateness))
printSequencingSolution(solution, schedule)
// Number of tasks
int NTASKS = 7;
// Release date of tasks
int REL[] = {2, 5, 4, 0, 0, 8, 9};
// Duration of tasks
int DUR[] = {5, 6, 8, 4, 2, 4, 2};
// Due date of tasks
int DUE[] = {10, 21, 15, 10, 5, 15, 22};
// Time horizon
int MAXTIME;
// Tasks to be planned
KTaskArray task = new KTaskArray();
// index variable
int indexTask;
// computing maximal time horizon;
int SUMDUR = 0;
for (indexTask = 0; indexTask < NTASKS; indexTask++)
{
SUMDUR += DUR[indexTask];
}
MAXTIME = 0;
for (indexTask = 0; indexTask < NTASKS; indexTask++)
{
if (REL[indexTask] + DUR[indexTask] > MAXTIME)
{
MAXTIME = REL[indexTask] + SUMDUR;
}
}
// Creation of the problem in this session
KProblem problem = new KProblem(session, "B-4 Sequencing");
// Creation of the schedule object with time horizon (0..MAXTIME)
KSchedule schedule = new KSchedule(problem, "B-4 Sequencing schedule", 0, 100);
// Resource (machine)
KUnaryResource cpresource = new KUnaryResource(schedule, "machine");
// building each tasks with fixed duration
for (indexTask = 0; indexTask < NTASKS; indexTask++)
{
task.add(new KTask(schedule, "T" + indexTask, DUR[indexTask], cpresource));
task.getElt(indexTask).getStartDateVar().setInf(REL[indexTask]);
}
// propagating problem
if (problem.propagate())
{
System.out.println("Problem is infeasible");
exit(1);
}
// **********************
// Objective 1 : Makespan
// **********************
schedule.optimize();
// solution printing
System.out.println("Completion time: " + problem.getSolution().getValue(schedule.getMakeSpan()));
System.out.print("Rel\t");
for (indexTask = 0; indexTask < NTASKS; indexTask++)
{
System.out.print(REL[indexTask] + "\t");
}
System.out.print("\nDur\t");
for (indexTask = 0; indexTask < NTASKS; indexTask++)
{
System.out.print(DUR[indexTask] + "\t");
}
System.out.print("\nStart\t");
for (indexTask = 0; indexTask < NTASKS; indexTask++)
{
System.out.print(problem.getSolution().getValue(task.getElt(indexTask).getStartDateVar()) + "\t");
}
System.out.print("\nEnd\t");
for (indexTask = 0; indexTask < NTASKS; indexTask++)
{
System.out.print(problem.getSolution().getValue(task.getElt(indexTask).getEndDateVar()) + "\t");
}
System.out.print("\nDue\t");
for (indexTask = 0; indexTask < NTASKS; indexTask++)
{
System.out.print(DUE[indexTask] + "\t");
}
System.out.print("\n");
// ***************************************
// Objective 2 : Average completion time :
// ***************************************
KLinTerm totalCompletionTerm = new KLinTerm();
for (indexTask = 0; indexTask < NTASKS; indexTask++)
{
totalCompletionTerm.add(task.getElt(indexTask).getEndDateVar(), 1);
}
KIntVar averageCompletion = new KIntVar(problem, "average completion", 0, 1000);
// Create the linear combination averageCompletion - totalCompletionTerm
totalCompletionTerm.add(averageCompletion, -1);
KNumVarArray intVarArrayToSet = totalCompletionTerm.getLvars();
KDoubleArray coeffsToSet = totalCompletionTerm.getCoeffs();
problem.post(new KNumLinComb("", coeffsToSet, intVarArrayToSet, 0, KNumLinComb.LinCombOperator.Equal));
schedule.setObjective(averageCompletion);
schedule.optimize();
// solution printing
System.out.println("Completion time: " + problem.getSolution().getValue(schedule.getMakeSpan()));
System.out.println("average: " + problem.getSolution().getValue(averageCompletion));
System.out.print("\nRel\t");
for (indexTask = 0; indexTask < NTASKS; indexTask++)
{
System.out.print(REL[indexTask] + "\t");
}
System.out.print("\nDur\t");
for (indexTask = 0; indexTask < NTASKS; indexTask++)
{
System.out.print(DUR[indexTask] + "\t");
}
System.out.print("\nStart\t");
for (indexTask = 0; indexTask < NTASKS; indexTask++)
{
System.out.print(problem.getSolution().getValue(task.getElt(indexTask).getStartDateVar()) + "\t");
}
System.out.print("\nEnd\t");
for (indexTask = 0; indexTask < NTASKS; indexTask++)
{
System.out.print(problem.getSolution().getValue(task.getElt(indexTask).getEndDateVar()) + "\t");
}
System.out.print("\nDue\t");
for (indexTask = 0; indexTask < NTASKS; indexTask++)
{
System.out.print(DUE[indexTask] + "\t");
}
System.out.print("\n");
// *****************************
// Objective 3 : total lateness:
// *****************************
// Lateness of job at position k
KIntVarArray late = new KIntVarArray();
for (indexTask = 0; indexTask < NTASKS; indexTask++)
{
late.add(new KIntVar(problem, "late(" + indexTask + ")", 0, MAXTIME));
problem.post(new KGreaterOrEqualXyc(late.getElt(indexTask), task.getElt(indexTask).getEndDateVar(), -DUE[indexTask]));
}
KLinTerm totLatTerm = new KLinTerm();
// building each tasks with fixed time horizon (0..HORIZON)
for (indexTask = 0; indexTask < NTASKS; indexTask++)
{
// Late jobs: completion time exceeds the due date
// Create the linear combination late.getElt(indexTask) - comp.getElt(indexTask) + due.getElt(indexTask)
KLinTerm linearTerm = new KLinTerm();
linearTerm.add(late.getElt(indexTask), 1);
}
KIntVar totLate = new KIntVar(problem, "total lateness", 0, 1000);
totLatTerm.add(totLate, -1);
// add the linear combination equality startDates[3] - 1 * startDates[0] - varObj == 0
KNumVarArray intVarArrayToSet_totLatTerm = totLatTerm.getLvars();
KDoubleArray coeffsToSet_totLatTerm = totLatTerm.getCoeffs();
problem.post(new KNumLinComb("", coeffsToSet_totLatTerm, intVarArrayToSet_totLatTerm, 0, KNumLinComb.LinCombOperator.Equal));
schedule.setObjective(totLate);
schedule.optimize();
// solution printing
System.out.println("Completion time: " + problem.getSolution().getValue(schedule.getMakeSpan()));
System.out.println("average: " + problem.getSolution().getValue(averageCompletion));
System.out.println("Tardiness: " + problem.getSolution().getValue(totLate));
System.out.print("\nRel\t");
for (indexTask = 0; indexTask < NTASKS; indexTask++)
{
System.out.print(REL[indexTask] + "\t");
}
System.out.print("\nDur\t");
for (indexTask = 0; indexTask < NTASKS; indexTask++)
{
System.out.print(DUR[indexTask] + "\t");
}
System.out.print("\nStart\t");
for (indexTask = 0; indexTask < NTASKS; indexTask++)
{
System.out.print(problem.getSolution().getValue(task.getElt(indexTask).getStartDateVar()) + "\t");
}
System.out.print("\nEnd\t");
for (indexTask = 0; indexTask < NTASKS; indexTask++)
{
System.out.print(problem.getSolution().getValue(task.getElt(indexTask).getEndDateVar()) + "\t");
}
System.out.print("\nDue\t");
for (indexTask = 0; indexTask < NTASKS; indexTask++)
{
System.out.print(DUE[indexTask] + "\t");
}
System.out.print("\nLate\t");
for (indexTask = 0; indexTask < NTASKS; indexTask++)
{
System.out.print(problem.getSolution().getValue(late.getElt(indexTask)) + "\t");
}
System.out.print("\n");
Results¶
This model produces similar results as those reported for the model versions in Section 11.3. Following figure shows the Gantt chart display of the solution. Above the Gantt chart we can see the resource usage display: the machine is used without interruption by the tasks, that is, even if we relaxed the constraints given by the release times and due dates it would not have been possible to generate a schedule terminating earlier.
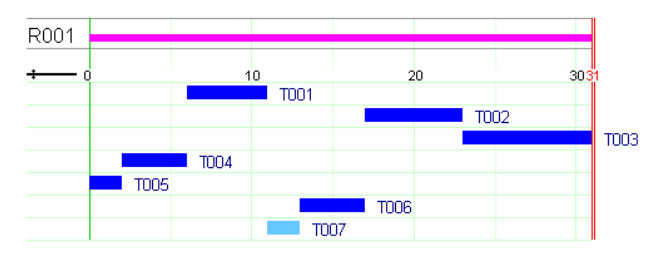
Fig. 12 Solution display¶
Cumulative scheduling: discrete resources¶
The problem described in this section is taken from Section 9.4 Backing up files of the book Applications of optimization with Xpress-MP.
Our task is to save sixteen files of the following sizes: 46kb, 55kb, 62kb, 87kb, 108kb, 114kb, 137kb, 164kb, 253kb, 364kb, 372kb, 388kb, 406kb, 432kb, 461kb, and 851kb onto empty disks of 1.44Mb capacity. How should the files be distributed in order to minimize the number of floppy disks used?
Model formulation¶
This problem belongs to the class of binpacking problems. We show here how it may be formulated and solved as a cumulative scheduling problem, where the disks are the resource and the files the tasks to be scheduled. The floppy disks may be represented as a single, discrete resource disks, where every time unit stands for one disk. The resource capacity corresponds to the disk capacity. We represent every file 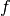 by a task object
by a task object 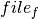 , with a fixed duration of 1 unit and a resource requirement that corresponds to the given size
, with a fixed duration of 1 unit and a resource requirement that corresponds to the given size 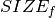 of the file. The start field of the task then indicates the choice of the disk for saving this file. The objective is to minimize the number of disks that are used, which corresponds to minimizing the largest value taken by the ‘start’ fields of the tasks (that is, the number of the disk used for saving a file). We thus have the following model.
of the file. The start field of the task then indicates the choice of the disk for saving this file. The objective is to minimize the number of disks that are used, which corresponds to minimizing the largest value taken by the ‘start’ fields of the tasks (that is, the number of the disk used for saving a file). We thus have the following model.

Implementation¶
The implementation with Artelys-Kalis is quite straightforward. We define a resource of the type KDiscreteResource, indicating its total capacity. The definition of the tasks is similar to what we have seen in the previous example.
// Number of floppy disks
int ND;
// Number of files
int NBFILES = 16;
// Floppy disk size
int CAP = 1440;
// Size of files to be saved
int SIZE[] = {46 ,55 ,62 ,87 ,108, 114, 137, 164, 253, 364, 372 ,388 ,406 ,432 ,461 ,851};
// Tasks (= files to be saved)
KTaskArray files;
// index variable
int indexTask;
// Provide a sufficiently large number of disks
int sumsize = 0;
for (indexTask = 0;indexTask < NBFILES; indexTask++) {
sumsize += SIZE[indexTask];
}
ND = ceil(sumsize / (float)(CAP));
// Creation of the problem in this session
KProblem problem(session,"D-4 Bin packing ");
// Creation of the schedule object with time horizon (0..ND)
KSchedule schedule(problem,"D-4 Bin packing (CP) schedule",0,ND);
// Setting up the resource (capacity limit of disks)
KDiscreteResource disks(schedule,"disks",CAP);
char name[80];
// Setting up the tasks
for (indexTask = 0;indexTask < NBFILES; indexTask++) {
sprintf(name,"File%i",indexTask);
files += * (new KTask(schedule,name,1) ) ;
files[indexTask].requires(disks,SIZE[indexTask]);
}
// propagating problem
if (problem.propagate()) {
printf("Problem is infeasible\n");
exit(1);
}
// look for optimal schedule
int result = schedule.optimize();
// solution printing
printf("Number of disks used: %f\n", problem.getSolution().getObjectiveValue() ) ;
int d;
for (d=1;d<=problem.getSolution().getObjectiveValue();d++) {
printf("disk %i: ",d);
int sumd = 0;
for (indexTask = 0;indexTask < NBFILES; indexTask++) {
if (problem.getSolution().getValue(*files[indexTask].getStartDateVar()) == d-1) {
printf("%i ",SIZE[indexTask]);
sumd += SIZE[indexTask];
}
}
printf(" space used: %i\n",sumd);
}
from kalis import *
import math
### Data creation
# Number of files
nb_files = 16
# Floppy disk size
capacity = 1440
# Size of files to be saved
file_sizes = [46, 55, 62, 87, 108, 114, 137, 164, 253, 364, 372, 388, 406, 432, 461, 851]
# Number of floppy disks
nb_disks = math.ceil(sum(file_sizes) / float(capacity))
### Creation of the problem
# Creation of the Kalis session
session = KSession()
# Creation of the problem in this session
problem = KProblem(session, "D-4 Bin packing")
# Creation of the schedule object with time horizon (0..nb_disk)
schedule = KSchedule(problem,"D-4 Bin packing (CP) schedule", 0, nb_disks);
# Setting up the resource (capacity limit of disks)
disks = KDiscreteResource(schedule, "disks", capacity)
# Tasks (= files to be saved)
files = KTaskArray()
for task_index in range(nb_files):
files += KTask(schedule, "File%d" % task_index, 1)
files[task_index].requires(disks, file_sizes[task_index])
### Solve the problem
# First propagation of the problem
if problem.propagate():
print("Problem is infeasible")
sys.exit(1)
### minimize the makespan (i.e. the number of used disks)
result = schedule.optimize()
if result:
solution = problem.getSolution()
nb_used_disks = int(solution.getObjectiveValue())
print("Number of disks used: %d" % nb_used_disks)
for d in range(1, nb_used_disks + 1):
print("disk %d: " % d, end='')
space_used = 0
for task_index in range(nb_files):
if solution.getValue(files[task_index].getStartDateVar()) == d - 1:
print(file_sizes[task_index], end=" ")
space_used += file_sizes[task_index]
print(" space used: %f" % space_used)
// Number of floppy disks
int ND;
// Number of files
int NBFILES = 16;
// Floppy disk size
int CAP = 1440;
// Size of files to be saved
int SIZE[] = {46,55,62,87,108, 114, 137, 164, 253, 364, 372,388,406,432,461,851};
// Tasks (= files to be saved)
KTaskArray files = new KTaskArray();
// index variable
int indexTask;
// Provide a sufficiently large number of disks
int sumsize = 0;
for (indexTask = 0; indexTask < NBFILES; indexTask++)
{
sumsize += SIZE[indexTask];
}
ND = (int) Math.ceil(sumsize / (float)(CAP));
// Creation of the problem in this session
KProblem problem = new KProblem(session,"D-4 Bin packing");
// Creation of the schedule object with time horizon (0..ND)
KSchedule schedule = new KSchedule(problem,"D-4 Bin packing (CP) schedule",0,ND);
// Setting up the resource (capacity limit of disks)
KDiscreteResource disks = new KDiscreteResource(schedule,"disks",CAP);
// Setting up the tasks
for (indexTask = 0; indexTask < NBFILES; indexTask++)
{
files.add(new KTask(schedule,"File" + indexTask,1) ) ;
files.getElt(indexTask).requires(disks,SIZE[indexTask]);
}
// propagating problem
if (problem.propagate())
{
System.out.println("Problem is infeasible");
exit(1);
}
// look for optimal schedule
if(schedule.optimize()==0)
{
System.out.println("Problem is infeasible");
return;
}
// solution printing
System.out.println("Number of disks used: " + problem.getSolution().getObjectiveValue());
int d;
for (d=1; d <=problem.getSolution().getObjectiveValue(); d++)
{
System.out.print("disk " + d + " : ");
int sumd = 0;
for (indexTask = 0; indexTask < NBFILES; indexTask++)
{
if (problem.getSolution().getValue(files.getElt(indexTask).getStartDateVar()) == d-1)
{
System.out.print(SIZE[indexTask] + " ");
sumd += SIZE[indexTask];
}
}
System.out.println(" space used: " + sumd);
}
Results¶
Running the model results in the solution shown below, that is, 3 disks are needed for backing up all the files.
Number of disks used: 3
disk 1: 46 ,55 ,62 ,87 ,108 ,137 ,164 ,372 ,406 , space used: 1437
disk 2: 114 ,461 ,851 , space used: 1426
disk 3: 253 ,364 ,388 ,432 , space used: 1437
The visualization of the results is shown in figure below with the resource usage profile at the top and the task Gantt chart in the lower half.
Fig. 13 Graphical representation of solution for the backup files model¶
Alternative formulation without scheduling¶
Instead of defining task and resource objects it is also possible to formulate this problem with a KCumulativeResourceConstraint constraint over standard finite domain variables that represent the different attributes of tasks without being grouped into a predefined object. A single KCumulativeResourceConstraint constraint expresses the problem of scheduling a set of tasks on one discrete resource by establishing the following relations between its arguments (five arrays of decision variables for the properties related to tasks start, duration, end, resource use and size all indexed by the same set  and a constant or time-indexed resource capacity):
and a constant or time-indexed resource capacity):
![& \forall j \in R : start_j + duration_j = end_j \\
& \forall j \in R : use_j.duration = size_j \\
& \forall t \in TIMES : sum_{j \in R | t \in [UB(start_j), ..., LB(end_j)]} use_j \leq CAP_t \\](_images/math/687bfcec1c03707a6ee2d983ebcc6b3b859fc15e.png)
where UB stands for upper bound and LB for lower bound of a decision variable. Let savef denote the disk used for saving a file and  the space used by the file (
the space used by the file (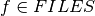 ). As with scheduling objects, the start property of a task corresponds to the disk chosen for saving the file, and the resource requirement of a task is the file size. Since we want to save every file onto a single disk, the duration
). As with scheduling objects, the start property of a task corresponds to the disk chosen for saving the file, and the resource requirement of a task is the file size. Since we want to save every file onto a single disk, the duration 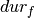 is fixed to 1. The remaining task properties end and size (
is fixed to 1. The remaining task properties end and size (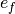 and
and 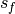 ) that need to be provided in the formulation of cumulative constraints are not really required for our problem; their values are determined by the other three properties.
) that need to be provided in the formulation of cumulative constraints are not really required for our problem; their values are determined by the other three properties.
Implementation¶
The following model implements the second version using the cumulative constraint.
// Number of floppy disks
int ND;
// Number of files
int NBFILES = 16;
// Floppy disk size
int CAP = 1440;
// Size of files to be saved
int SIZE[] = {46 ,55 ,62 ,87 ,108, 114, 137, 164, 253, 364, 372 ,388 ,406 ,432 ,461 ,851};
// index variable
int indexTask;
// Disk a file is saved on
KIntVarArray save;
// Space used by file on disk
KIntVarArray use;
// Auxiliary arrays for 'cumulative'
KIntVarArray dur,e,s;
// Number of disks used
KIntVar * diskuse;
// temporary array
KIntArray FSORT;
// Provide a sufficiently large number of disks
int sumsize = 0;
for (indexTask = 0;indexTask < NBFILES; indexTask++) {
sumsize += SIZE[indexTask];
}
ND = ceil(sumsize / (float)(CAP));
// Creation of the problem in this session
KProblem problem(session,"D-4 Bin packing ");
char name[80];
// Setting up the tasks
for (indexTask = 0;indexTask < NBFILES; indexTask++) {
sprintf(name,"save(%i)",indexTask);
save += * ( new KIntVar( problem , name,0,ND-1 ) ) ;
sprintf(name,"use(%i)",indexTask);
use += * ( new KIntVar( problem , name,SIZE[indexTask],SIZE[indexTask]) );
sprintf(name,"dur(%i)",indexTask);
dur += * ( new KIntVar( problem , name,1,1) ) ;
sprintf(name,"size(%i)",indexTask);
s += * ( new KIntVar( problem , name,SIZE[indexTask],SIZE[indexTask]) ) ;
sprintf(name,"end(%i)",indexTask);
e += * ( new KIntVar( problem , name,1,ND) ) ;
}
diskuse = new KIntVar(problem,"diskuse",0,ND);
// Limit the number of disks used
problem.post(KMax("maxdisk",*diskuse,save));
// Capacity limit of disks
problem.post(KCumulativeResourceConstraint(problem ,save, e,dur, use, s, CAP));
// propagating problem
if (problem.propagate()) {
printf("Problem is infeasible\n");
exit(1);
}
// Definition of search strategy
KBranchingSchemeArray strategy;
strategy += KAssignVar(KSmallestMin(),KMinToMax(),save);
// Creation of the solver
KSolver solver(problem, strategy);
// minimize disk usage
problem.setSense(KProblem::Minimize);
problem.setObjective(*diskuse);
// Minimize the total number of disks used
int result = solver.optimize();
// solution printing
printf("Number of disks used: %f\n", problem.getSolution().getObjectiveValue()+1 );
int d;
for (d=0;d<=problem.getSolution().getObjectiveValue();d++) {
printf("disk %i: ",d);
int sumd = 0;
for (indexTask = 0;indexTask < NBFILES; indexTask++) {
if (problem.getSolution().getValue(save[indexTask]) == d) {
printf("%i ",SIZE[indexTask]);
sumd += SIZE[indexTask];
}
}
printf(" space used: %i\n",sumd);
}
from kalis import *
import math
### Data creation
# Number of files
nb_files = 16
# Floppy disk size
capacity = 1440
# Size of files to be saved
file_sizes = [46, 55, 62, 87, 108, 114, 137, 164, 253, 364, 372, 388, 406, 432, 461, 851]
# Number of floppy disks
nb_disks = math.ceil(sum(file_sizes) / float(capacity))
### Creation of the problem
# Creation of the Kalis session
session = KSession()
# Creation of the problem in this session
problem = KProblem(session, "D-4 Bin packing")
### Variables creation
# Disk where each file is saved
save = KIntVarArray()
# Space used by each file
use = KIntVarArray()
# Auxiliary arrays for 'cumulative' resource constraint
dur = KIntVarArray()
s = KIntVarArray()
e = KIntVarArray()
for task_index in range(nb_files):
save += KIntVar(problem, "save(%d)" % task_index, 0, nb_disks - 1)
use += KIntVar(problem, "use(%d)" % task_index, file_sizes[task_index], file_sizes[task_index])
dur += KIntVar(problem, "dur(%d)" % task_index, 1, 1)
s += KIntVar(problem, "size(%d)" % task_index, file_sizes[task_index], file_sizes[task_index])
e += KIntVar(problem, "end(%d)" % task_index, 1, nb_disks)
# Number of used disks
nb_used_disks = KIntVar(problem, "diskuse", 0, nb_disks)
### Constraint creation
# Limit the number of used disks
problem.post(KMax("maxdisk", nb_used_disks, save))
# Capacity limit of disks
problem.post(KCumulativeResourceConstraint(problem, save, e, dur, s, use, capacity))
### Solve the problem
# First propagation of the problem
if problem.propagate():
print("Problem is infeasible")
sys.exit(1)
# Definition of search strategy
strategy = KBranchingSchemeArray()
strategy += KAssignVar(KSmallestMin(), KMinToMax(), save)
# Creation of the solver
solver = KSolver(problem, strategy)
# Set problem objective
problem.setSense(KProblem.Minimize)
problem.setObjective(nb_used_disks)
# Minimize the total number of disks used
result = solver.optimize()
if result:
solution = problem.getSolution()
nb_used_disks = int(solution.getObjectiveValue()) + 1
print("Number of disks used: %d" % nb_used_disks)
for d in range(nb_used_disks):
print("disk %d: " % d, end='')
sumd = 0
for task_index in range(nb_files):
if solution.getValue(save[task_index]) == d:
print("%d" % file_sizes[task_index], end=" ")
sumd += file_sizes[task_index]
print(" space used: %f" % sumd)
// Number of floppy disks
int ND;
// Number of files
int NBFILES = 16;
// Floppy disk size
int CAP = 1440;
// Size of files to be saved
int SIZE[] = {46, 55, 62, 87, 108, 114, 137, 164, 253, 364, 372, 388, 406, 432, 461, 851};
// index variable
int indexTask;
// Disk a file is saved on
KIntVarArray save = new KIntVarArray();
// Space used by file on disk
KIntVarArray use = new KIntVarArray();
// Auxiliary arrays for 'cumulative'
KIntVarArray dur = new KIntVarArray();
KIntVarArray e = new KIntVarArray();
KIntVarArray s = new KIntVarArray();
// Number of disks used
KIntVar diskuse = new KIntVar();
// Provide a sufficiently large number of disks
int sumsize = 0;
for (indexTask = 0; indexTask < NBFILES; indexTask++)
{
sumsize += SIZE[indexTask];
}
ND = (int) Math.ceil(sumsize / (float)(CAP));
// Creation of the problem in this session
KProblem problem = new KProblem(session,"D-4 Bin packing ");
// Setting up the tasks
for (indexTask = 0; indexTask < NBFILES; indexTask++)
{
save.add(new KIntVar(problem, "save(" + indexTask + ")",0,ND-1 ) ) ;
use.add(new KIntVar(problem, "use(" + indexTask + ")", SIZE[indexTask], SIZE[indexTask]) );
dur.add(new KIntVar(problem, "dur(" + indexTask + ")",1,1) ) ;
s.add(new KIntVar(problem, "size(" + indexTask + ")", SIZE[indexTask], SIZE[indexTask]) ) ;
e.add(new KIntVar(problem, "end(" + indexTask + ")",1,ND) ) ;
}
diskuse = new KIntVar(problem,"diskuse",0,ND);
// Limit the number of disks used
problem.post(new KMax("maxdisk",diskuse,save));
// Capacity limit of disks
problem.post(new KCumulativeResourceConstraint(problem,save,e,dur,use,s,CAP));
// propagating problem
if (problem.propagate())
{
System.out.println("Problem is infeasible");
exit(1);
}
// Definition of search strategy
KBranchingSchemeArray strategy = new KBranchingSchemeArray();
strategy.add(new KAssignVar(new KSmallestMin(), new KMinToMax(),save));
// Creation of the solver
KSolver solver= new KSolver(problem);
// minimize disk usage
problem.setSense(KProblem.Sense.Minimize);
problem.setObjective(diskuse);
// Minimize the total number of disks used
solver.optimize();
// solution printing
System.out.println("Number of disks used: " + problem.getSolution().getObjectiveValue()+1 );
int d;
for (d=0; d <=problem.getSolution().getObjectiveValue(); d++)
{
System.out.print("disk " + d + " :");
int sumd = 0;
for (indexTask = 0; indexTask < NBFILES; indexTask++)
{
if (problem.getSolution().getValue(save.getElt(indexTask)) == d)
{
System.out.print(SIZE[indexTask] + " ");
sumd += SIZE[indexTask];
}
}
System.out.println(" space used: " + sumd);
}
The solution produced by the execution of this model has the same objective function value, but the distribution of the files to the disks is not exactly the same: this problem has several different optimal solutions, in particular those that may be obtained be interchanging the order numbers of the disks. To shorten the search in such a case it may be useful to add some symmetry breaking constraints that reduce the size of the search space by removing a part of the feasible solutions. In the present example we may, for instance, assign the biggest file to the first disk and the second largest to one of the first two disks, and so on, until we reach a lower bound on the number of disks required (a safe lower bound estimate is given by rounding up to the next larger integer the sum of files sizes divided by the disk capacity).
Renewable and non-renewable resources¶
Besides the distinction disjunctive–cumulative or unary–discrete that we have encountered in the previous sections there are other ways of describing or classifying resources. Another important property is the concept of renewable versus non-renewable resources. The previous examples have shown instances of renewable resources (machine capacity, manpower etc.): the amount of resource used by a task is released at its completion and becomes available for other tasks. In the case of non-renewable resources (e.g. money, raw material, intermediate products), the tasks using the resource consume it, that is, the available quantity of the resource is diminuished by the amount used up by processing a task. Instead of using resources tasks may also produce certain quantities of resource. Again, we may have tasks that provide an amount of resource during their execution (renewable resources) or tasks that add the result of their production to a stock of resource (non-renewable resources).
Let us now see how to formulate the following problem: we wish to schedule five jobs P1 to P5 representing two stages of a production process. P1 and P2 produce an intermediate product that is needed by the jobs of the final stage (P3 to P5). For every job we are given its minimum and maximum duration, its cost or, for the jobs of the final stage, its profit contribution. There may be two cases, namely model A: the jobs of the first stage produce a given quantity of intermediate product (such as electricity, heat, steam) at every point of time during their execution, this intermediate product is consumed immediately by the jobs of the final stage. Model B: the intermediate product results as ouput from the jobs of the first stage and is required as input to start the jobs of the final stage. The intermediate product in model A is a renewable resource and in model B we have the case of a non-renewable resource.
Model formulation¶
Let 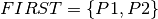 be the set of jobs in the first stage,
be the set of jobs in the first stage, 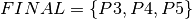 the jobs of the second stage, and the set
the jobs of the second stage, and the set  the union of all jobs. For every job we are given its minimum and maximum duration
the union of all jobs. For every job we are given its minimum and maximum duration 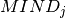 and
and 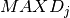 respectively.
respectively. 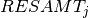 is the amount of resource needed as input or resulting as output from a job. Furthermore we have a cost
is the amount of resource needed as input or resulting as output from a job. Furthermore we have a cost 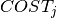 for jobs of the first stage and a profit
for jobs of the first stage and a profit 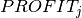 for jobs of the final stage.
for jobs of the final stage.
Model A (renewable resource) : The case of a renewable resource is formulated by the following model. Notice that the resource capacity is set to 0 indicating that the only available quantities of resource are those produced by the jobs of the first production stage.

Model B (non-renewable resource) : In analogy to the model A we formulate the second case as follows.

However, this model does not entirely correspond to the problem description above since the provision of the intermediate product occurs at the start of a task. To remedy this problem we may introduce an auxiliary task 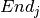 for every job in the first stage. The auxiliary job has duration 0, the same completion time as the original job and provides the intermediate product in the place of the original job.
for every job in the first stage. The auxiliary job has duration 0, the same completion time as the original job and provides the intermediate product in the place of the original job.
Implementation¶
The following model implements case A. We use the default scheduling indicating by the value true for the optional second argument that we wish to maximize the objective function.
enum JOBS{P1,P2,P3,P4,P5};
char * names[] = {"P1","P2","P3","P4","P5"};
// Limits on job durations
int MIND[] = {3,4,0,4,10};
int MAXD[] = {15,26,15,25,20};
// Resource use/production
int RESAMT[] = {10,12,5,8,7};
// Time horizon
int HORIZON = 35;
// Profit from production
double PROFIT[] = {0,0,5.5,7,6.2};
// Cost of production
double COST[] = {1.8,1.6,0,0,0};
// Available resource quantity
int CAP = 0;
KFloatVar * totalProfit;
// Task objects for jobs
KTaskArray task;
// Non-renewable resource (intermediate prod.)
KDiscreteResource * intermProd;
// Creation of the problem in this session
KProblem problem(session,"Renewable resource");
// Creation of the schedule object with time horizon (0..HORIZON)
KSchedule schedule(problem,"Renewable resource schedule",0,HORIZON);
// Setting up the tasks
int indexJob;
for (indexJob = P1; indexJob <= P5; indexJob ++ ) {
task += * ( new KTask(schedule, names[indexJob],0,HORIZON-MIND[indexJob],MIND[indexJob],MAXD[indexJob]) ) ;
task[indexJob].getEndDateVar()->setSup(HORIZON);
}
// Setting up resources
intermProd = new KDiscreteResource(schedule,"IntP",CAP);
// Providing tasks
for (indexJob = P1; indexJob <= P2; indexJob ++ ) {
task[indexJob].provides(*intermProd,RESAMT[indexJob]);
}
// Requiring tasks
for (indexJob = P3; indexJob <= P5; indexJob ++ ) {
task[indexJob].requires(*intermProd,RESAMT[indexJob]);
}
// Objective function: total profit
totalProfit = new KFloatVar(problem,"totalProfit");
KLinTerm linTerm;
for (indexJob = P3; indexJob <= P5; indexJob ++ ) {
linTerm = linTerm + PROFIT[indexJob] * (*task[indexJob].getDurationVar());
}
for (indexJob = P1; indexJob <= P5; indexJob ++ ) {
linTerm = linTerm - COST[indexJob] * (*task[indexJob].getDurationVar());
}
problem.post(*totalProfit == linTerm);
// closing the schedule
schedule.close();
// propagating problem
if (problem.propagate()) {
printf("Problem is infeasible\n");
exit(1);
}
// maximizing totalProfit
schedule.setObjective(*totalProfit);
schedule.getProblem()->setSense(KProblem::Maximize);
schedule.setFunctionPointers(NULL,sfound,nfound,NULL,NULL,&problem);
// Find optimal schedule
int result = schedule.optimize();
// Solution printing
printf("Total profit: %f\n", problem.getSolution().getValue(*totalProfit));
printf("Job\tStart\tEnd\tDuration");
for (indexJob = P1; indexJob <= P5; indexJob ++ ) {
printf("%i\t%i\t%i\t%i\n",indexJob, problem.getSolution().getValue(*task[indexJob].getStartDateVar()), problem.getSolution().getValue(*task[indexJob].getEndDateVar()), problem.getSolution().getValue(*task[indexJob].getDurationVar()));
}
from kalis import *
### Data creation
jobs = ["P1", "P2", "P3", "P4", "P5"]
nb_jobs = len(jobs)
providings_jobs_index = [0, 1]
requiring_jobs_index = [2, 3, 4]
# Limits on job durations
min_durations = [3, 4, 0, 4, 10]
max_durations = [15, 26, 15, 25, 20]
# Resource use/production
resource_amounts = [10, 12, 5, 8, 7]
# Time horizon
horizon = 35
# Profit from production
profits = [0, 0, 5.5, 7, 6.2]
# Cost of production
costs = [1.8, 1.6, 0, 0, 0]
# Available resource quantity
capacity = 0
### Creation of the problem
# Creation of the Kalis session
session = KSession()
# Creation of the problem in this session
problem = KProblem(session, "Renewable resource")
# Creation of the schedule object with time horizon (0..HORIZON)
schedule = KSchedule(problem, "Renewable resource schedule", 0, horizon)
### Variables and constraints creation
# Task objects for jobs
tasks = KTaskArray()
for j in range(nb_jobs):
tasks += KTask(schedule, jobs[j], 0, horizon - min_durations[j], min_durations[j], max_durations[j])
tasks[j].getEndDateVar().setSup(horizon)
# Renewable resource (intermediate prod)
intermediate_production = KDiscreteResource(schedule, "IntP", capacity)
# Providing tasks
for j in providings_jobs_index:
tasks[j].provides(intermediate_production, resource_amounts[j])
# Requiring tasks
for j in requiring_jobs_index:
tasks[j].requires(intermediate_production, resource_amounts[j])
# Objective function: total profit
total_profit = KFloatVar(problem ,"totalProfit")
profits_sum = sum((profits[j] - costs[j]) * tasks[j].getDurationVar() for j in range(nb_jobs))
problem.post(total_profit == profits_sum)
# Closing schedule (no tasks or resources can be added after that)
schedule.close()
### Solve the problem
# First propagation of the problem
if problem.propagate():
print("Problem is infeasible")
sys.exit(1)
# Set problem objective and sense
schedule.setObjective(total_profit)
schedule.getProblem().setSense(KProblem.Maximize)
# Find optimal schedule
result = schedule.optimize()
if result:
solution = problem.getSolution()
print("Total profit: %f" % solution.getValue(total_profit))
print("Job\tStart\tEnd\tDuration")
for j in range(nb_jobs):
job_start = solution.getValue(tasks[j].getStartDateVar())
job_end = solution.getValue(tasks[j].getEndDateVar())
job_duration = solution.getValue(tasks[j].getDurationVar())
print("%s\t%d\t%d\t%d" % (jobs[j], job_start, job_end, job_duration))
// Number of jobs and names
int nbJobs = 5;
String[] names = { "P1","P2","P3","P4","P5"};
// Limits on job durations
int MIND[] = { 3, 4, 0, 4, 10 };
int MAXD[] = { 15, 26, 15, 25, 20 };
// Resource use/production
int RESAMT[] = { 10, 12, 5, 8, 7 };
// Time horizon
int HORIZON = 35;
// Profit from production
double PROFIT[] = { 0, 0, 5.5, 7, 6.2 };
// Cost of production
double COST[] = { 1.8, 1.6, 0, 0, 0 };
// Available resource quantity
int CAP = 0;
// Task objects for jobs
KTaskArray task = new KTaskArray();
// Creation of the problem in this session
KProblem problem = new KProblem(session, "Renewable resource");
// Creation of the schedule object with time horizon (0..HORIZON)
KSchedule schedule = new KSchedule(problem, "Renewable resource schedule", 0, HORIZON);
// Setting up the tasks
int indexJob;
for (indexJob = 0; indexJob < nbJobs; indexJob++)
{
task.add(new KTask(schedule, names[indexJob], 0, HORIZON - MIND[indexJob], MIND[indexJob], MAXD[indexJob]));
task.getElt(indexJob).getEndDateVar().setSup(HORIZON);
}
// Setting up non-renewable resource (intermediate prod.)
KDiscreteResource intermProd = new KDiscreteResource(schedule, "IntP", CAP);
// Providing tasks : two first jobs concerned
for (indexJob = 0; indexJob < 2; indexJob++)
{
task.getElt(indexJob).provides(intermProd, RESAMT[indexJob]);
}
// Requiring tasks : three last jobs concerned
for (indexJob = 2; indexJob < nbJobs; indexJob++)
{
task.getElt(indexJob).requires(intermProd, RESAMT[indexJob]);
}
// Objective function: total profit
KFloatVar totalProfit = new KFloatVar(problem, "totalProfit");
KLinTerm linTerm = new KLinTerm();
for (indexJob = 2; indexJob < nbJobs; indexJob++)
{
linTerm.add(task.getElt(indexJob).getDurationVar(),PROFIT[indexJob]);
}
for (indexJob = 0; indexJob < nbJobs; indexJob++)
{
linTerm.add(task.getElt(indexJob).getDurationVar(),- COST[indexJob]);
}
KNumVarArray intVarArrayToSet = linTerm.getLvars();
KDoubleArray coeffsToSet = linTerm.getCoeffs();
intVarArrayToSet.add(totalProfit);
coeffsToSet.add(-1);
problem.post(new KNumLinComb("",coeffsToSet,intVarArrayToSet,0,KNumLinComb.LinCombOperator.Equal));
// closing the schedule
schedule.close();
// propagating problem
if (problem.propagate())
{
System.out.println("Problem is infeasible");
exit(1);
}
// maximizing totalProfit
schedule.setObjective(totalProfit);
schedule.getProblem().setSense(KProblem.Sense.Maximize);
// Find optimal schedule
schedule.optimize();
// Solution printing
System.out.println("Total profit: " + problem.getSolution().getValue(totalProfit));
System.out.print("Job\tStart\tEnd\tDuration\n");
for (indexJob = 0; indexJob < nbJobs; indexJob++)
{
System.out.println(indexJob + "\t" + problem.getSolution().getValue(task.getElt(indexJob).getStartDateVar()) + "\t" + problem.getSolution().getValue(task.getElt(indexJob).getEndDateVar()) + "\t" + problem.getSolution().getValue(task.getElt(indexJob).getDurationVar()));
}
The model for case B adds the two auxiliary tasks (forming the set ENDFIRST) that mark the completion of the jobs in the first stage. The only other difference are the task properties produces and consumes that define the resource constraints. We only repeat the relevant part of the model:
enum JOBS{P1,P2,endP1,endP2,P3,P4,P5};
char * names[] = {"P1","P2","endP1","endP2","P3","P4","P5"};
// Limits on job durations
int MIND[] = {3,4,0,1,1,4,10};
int MAXD[] = {15,26,1,1,15,25,20};
// Resource use/production
int RESAMT[] = {0,0,10,12,5,8,7};
// Time horizon
int HORIZON = 35;
// Profit from production
double PROFIT[] = {0,0,0,0,5.5,7,6.2};
// Cost of production
double COST[] = {1.8,1.6,0,0,0,0,0};
// Available resource quantity
int CAP = 0;
KFloatVar * totalProfit;
// Task objects for jobs
KTaskArray task;
// Non-renewable resource (intermediate prod.)
KDiscreteResource * intermProd;
// Creation of the problem in this session
KProblem problem(session,"Renewable resource (B)");
// Creation of the schedule object with time horizon (0..HORIZON)
KSchedule schedule(problem,"Renewable resource (B) schedule",0,HORIZON);
// Setting up the tasks
int indexJob;
for (indexJob = P1; indexJob <= P5; indexJob ++ ) {
task += * ( new KTask(schedule, names[indexJob],0,HORIZON-MIND[indexJob],MIND[indexJob],MAXD[indexJob]) ) ;
task[indexJob].getEndDateVar()->setSup(HORIZON);
}
// Setting up resources
intermProd = new KDiscreteResource(schedule,"IntP",CAP,false);
// Providing tasks
for (indexJob = endP1; indexJob <= endP2; indexJob ++ ) {
task[indexJob].produces(*intermProd,RESAMT[indexJob]);
}
// Requiring tasks
for (indexJob = P3; indexJob <= P5; indexJob ++ ) {
task[indexJob].consumes(*intermProd,RESAMT[indexJob]);
}
problem.post(*task[endP1].getStartDateVar() == *task[P1].getEndDateVar());
problem.post(*task[endP2].getStartDateVar() == *task[P2].getEndDateVar());
task[endP1].setDuration(1);
task[endP2].setDuration(1);
// Objective function: total profit
totalProfit = new KFloatVar(problem,"totalProfit");
KLinTerm linTerm;
for (indexJob = P3; indexJob <= P5; indexJob ++ ) {
linTerm = linTerm + PROFIT[indexJob] * (*task[indexJob].getDurationVar());
}
for (indexJob = P1; indexJob <= P5; indexJob ++ ) {
linTerm = linTerm - COST[indexJob] * (*task[indexJob].getDurationVar());
}
problem.post(*totalProfit == linTerm);
from kalis import *
### Data creation
jobs = ["P1", "P2", "endP1", "endP2", "P3", "P4", "P5"]
nb_jobs = len(jobs)
producing_jobs_index = [2, 3]
consuming_jobs_index = [4, 5, 6]
# Limits on job durations
min_durations = [3, 4, 0, 1, 1, 4, 10]
max_durations = [15, 26, 1, 1, 15, 25, 20]
# Resource use/production
resource_amounts = [0, 0, 10, 12, 5, 8, 7]
# Time horizon
horizon = 35
# Profit from production
profits = [0, 0, 0, 0, 5.5, 7, 6.2]
# Cost of production
costs = [1.8, 1.6, 0, 0, 0, 0, 0]
# Available resource quantity
capacity = 0
### Creation of the problem
# Creation of the Kalis session
session = KSession()
# Creation of the problem in this session
problem = KProblem(session, "Non-Renewable resource (B)")
# Creation of the schedule object with time horizon (0..HORIZON)
schedule = KSchedule(problem, "Non-Renewable resource (B) schedule", 0, horizon)
### Variables and constraints creation
# Task objects for jobs
tasks = KTaskArray()
for j in range(nb_jobs):
tasks += KTask(schedule, jobs[j], 0, horizon - min_durations[j], min_durations[j], max_durations[j])
tasks[j].getEndDateVar().setSup(horizon)
# Non-renewable resource (intermediate prod)
intermediate_production = KDiscreteResource(schedule, "IntP", capacity, False)
# Producing tasks
for j in producing_jobs_index:
tasks[j].produces(intermediate_production, resource_amounts[j])
# Consuming tasks
for j in consuming_jobs_index:
tasks[j].consumes(intermediate_production, resource_amounts[j])
# Set auxiliary variables end dates and durations
problem.post(tasks[0].getEndDateVar() == tasks[2].getStartDateVar())
problem.post(tasks[1].getEndDateVar() == tasks[3].getStartDateVar())
tasks[2].setDuration(1)
tasks[3].setDuration(1)
# Objective function: total profit
total_profit = KFloatVar(problem ,"totalProfit")
profits_sum = sum((profits[j] - costs[j]) * tasks[j].getDurationVar() for j in range(nb_jobs))
problem.post(total_profit == profits_sum)
# Closing schedule (no tasks or resources can be added after that)
schedule.close()
### Solve the problem
# First propagation of the problem
if problem.propagate():
print("Problem is infeasible")
sys.exit(1)
# Set problem objective and sense
schedule.setObjective(total_profit)
schedule.getProblem().setSense(KProblem.Maximize)
# Find optimal schedule
result = schedule.optimize()
if result:
solution = problem.getSolution()
print("Total profit: %f" % solution.getValue(total_profit))
print("Job\tStart\tEnd\tDuration")
for j in range(nb_jobs):
job_start = solution.getValue(tasks[j].getStartDateVar())
job_end = solution.getValue(tasks[j].getEndDateVar())
job_duration = solution.getValue(tasks[j].getDurationVar())
print("%s\t%d\t%d\t%d" % (jobs[j], job_start, job_end, job_duration))
// Number of jobs and names
int nbJobs = 7;
String[] names = { "P1","P2","endP1","endP2","P3","P4","P5"};
// Limits on job durations
int MIND[] = { 3, 4, 0, 1, 1, 4, 10 };
int MAXD[] = { 15, 26, 1, 1, 15, 25, 20 };
// Resource use/production
int RESAMT[] = { 0, 0, 10, 12, 5, 8, 7 };
// Time horizon
int HORIZON = 35;
// Profit from production
double PROFIT[] = { 0, 0, 0, 0, 5.5, 7, 6.2 };
// Cost of production
double COST[] = { 1.8, 1.6, 0, 0, 0, 0, 0 };
// Available resource quantity
int CAP = 0;
// Task objects for jobs
KTaskArray task = new KTaskArray();
// Creation of the problem in this session
KProblem problem = new KProblem(session, "Renewable resource (B)");
// Creation of the schedule object with time horizon (0..HORIZON)
KSchedule schedule = new KSchedule(problem, "Renewable resource (B) schedule", 0, HORIZON);
// Setting up the tasks
int indexJob;
for (indexJob = 0; indexJob < nbJobs; indexJob++)
{
task.add(new KTask(schedule, names[indexJob], 0, HORIZON - MIND[indexJob], MIND[indexJob], MAXD[indexJob]));
task.getElt(indexJob).getEndDateVar().setSup(HORIZON);
}
// Setting up non-renewable resource (intermediate prod.)
KDiscreteResource intermProd = new KDiscreteResource(schedule, "IntP", CAP, 0);
// Providing tasks
for (indexJob = 2; indexJob < 4; indexJob++)
{
task.getElt(indexJob).produces(intermProd, RESAMT[indexJob]);
}
// Requiring tasks
for (indexJob = 4; indexJob < nbJobs; indexJob++)
{
task.getElt(indexJob).consumes(intermProd, RESAMT[indexJob]);
}
problem.post(new KEqualXyc(task.getElt(3).getStartDateVar(), task.getElt(1).getEndDateVar(),0));
problem.post(new KEqualXyc(task.getElt(4).getStartDateVar(), task.getElt(2).getEndDateVar(),0));
task.getElt(3).setDuration(1);
task.getElt(4).setDuration(1);
// Objective function: total profit
KFloatVar totalProfit = new KFloatVar(problem, "totalProfit");
KLinTerm linTerm = new KLinTerm();
for (indexJob = 4; indexJob < nbJobs; indexJob++)
{
linTerm.add(task.getElt(indexJob).getDurationVar(),PROFIT[indexJob]);
}
for (indexJob = 0; indexJob < nbJobs; indexJob++)
{
linTerm.add(task.getElt(indexJob).getDurationVar(),- COST[indexJob]);
}
KNumVarArray intVarArrayToSet = linTerm.getLvars();
KDoubleArray coeffsToSet = linTerm.getCoeffs();
intVarArrayToSet.add(totalProfit);
coeffsToSet.add(-1);
problem.post(new KNumLinComb("",coeffsToSet,intVarArrayToSet,0,KNumLinComb.LinCombOperator.Equal));
// closing the schedule
schedule.close();
// propagating problem
if (problem.propagate())
{
System.out.println("Problem is infeasible");
exit(1);
}
// maximizing totalProfit
schedule.setObjective(totalProfit);
schedule.getProblem().setSense(KProblem.Sense.Maximize);
// Find optimal schedule
schedule.optimize();
// Solution printing
System.out.println("Total profit: " + problem.getSolution().getValue(totalProfit));
System.out.print("Job\tStart\tEnd\tDuration\n");
for (indexJob = 0; indexJob < nbJobs; indexJob++)
{
System.out.println(indexJob + "\t" + problem.getSolution().getValue(task.getElt(indexJob).getStartDateVar()) + "\t" + problem.getSolution().getValue(task.getElt(indexJob).getEndDateVar()) + "\t" + problem.getSolution().getValue(task.getElt(indexJob).getDurationVar()));
}
Results¶
The behavior of the (default) search and the results of the two models are considerably different. The optimal solution with an objective of 344.9 for case B represented in figure Fig. 15 is proven within a fraction of a second. Finding a good solution for case A takes several seconds on a standard PC; finding the optimal solution (see figure Fig. 14) and proving its optimality requires several minutes of running time. The main reason for this poor behavior of the search is our choice of the objective function: the cost-based objective function does not propagate well and therefore does not help with pruning the search tree. A better choice for objective functions in scheduling problems generally are criteria involving the task decision variables (start, duration, or completion time, particularly the latter).
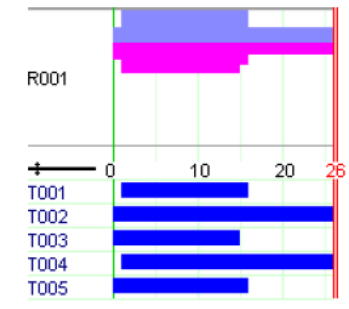
Fig. 14 Solution for case A (resource provision and requirement)¶
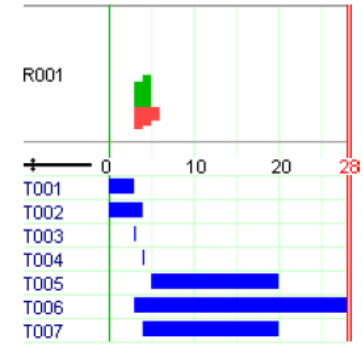
Fig. 15 Solution for case B (resource production and consumption)¶
Extensions: setup times¶
Consider once more the problem of planning the production of paint batches introduced in section Section 11.5. Between the processing of two batches the machine needs to be cleaned. The cleaning (or setup) times incurred are sequence-dependent and asymetric. The objective is to determine a production cycle of the shortest length.
Model formulation¶
For every job (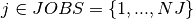 ), represented by a task object , we are given its processing duration . We also have a matrix of cleaning times
), represented by a task object , we are given its processing duration . We also have a matrix of cleaning times  with entries
with entries  indicating the duration of the cleaning operation if task precedes task
indicating the duration of the cleaning operation if task precedes task 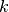 . The machine processing the jobs is modeled as a resource of unitary capacity, thus stating the disjunctions between the jobs.
. The machine processing the jobs is modeled as a resource of unitary capacity, thus stating the disjunctions between the jobs.
With the objective to minimize the makespan (completion time of the last batch) we obtain the following model:

The tricky bit in the formulation of the original problem is that we wish to minimize the cycle time, that is, the completion of the last job plus the setup required between the last and the first jobs in the sequence. Since our task-based model does not contain any information about the sequence or rank of the jobs we introduce auxiliary variables 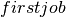 and
and 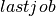 for the index values of the jobs in the first and last positions of the production cycle, and a variable
for the index values of the jobs in the first and last positions of the production cycle, and a variable 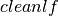 for the duration of the setup operation between the last and first tasks. The following constraints express the relations between these variables and the task objects:
for the duration of the setup operation between the last and first tasks. The following constraints express the relations between these variables and the task objects:
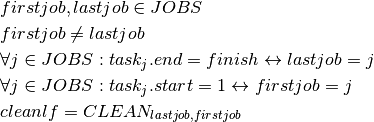
Minimizing the cycle time then corresponds to minimizing the sum 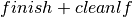 .
.
Implementation¶
The following model implements the task-based model formulated above. The setup times between tasks are set with the procedure KTask::setupTime() indicating the two task objects and the corresponding duration value.
// Number of paint batches (=jobs)
int NJ = 5;
// Durations of jobs
int DUR[] = {40, 35, 45 ,32 ,50};
// Cleaning times between jobs
KIntMatrix CLEAN(5,5,0,"CLEAN");
CLEAN[0][0] = 0;CLEAN[1][0] = 11;CLEAN[2][0] = 7;CLEAN[3][0] = 13;CLEAN[4][0] = 11;
CLEAN[0][1] = 5;CLEAN[1][1] = 0;CLEAN[2][1] = 13;CLEAN[3][1] = 15;CLEAN[4][1] = 15;
CLEAN[0][2] = 13;CLEAN[1][2] = 15;CLEAN[2][2] = 0;CLEAN[3][2] = 23;CLEAN[4][2]= 11;
CLEAN[0][3] = 9;CLEAN[1][3] = 13;CLEAN[2][3] = 5;CLEAN[3][3] = 0;CLEAN[4][3] = 3;
CLEAN[0][4] = 3;CLEAN[1][4] = 7;CLEAN[2][4] = 7;CLEAN[3][4] = 7;CLEAN[4][4] = 0;
KTaskArray task;
KUnaryResource *res;
KIntVar * firstjob,*lastjob,*cleanlf,*finish;
KIntVarArray L;
// Objective variable
KIntVar * cycleTime;
// Creation of the problem in this session
KProblem problem(session,"B-5 Paint production");
// Creation of the schedule
KSchedule schedule(problem,"B-5 Paint production Schedule",0,10000);
// Setting up the resource (formulation of the disjunction of tasks)
res = new KUnaryResource(schedule,"res");
// Setting up the tasks
char name[80];
int j,i;
for (j=0;j<NJ;j++) {
sprintf(name,"Task%i",j+1);
task += (* new KTask(schedule,name,DUR[j],*res) );
// Start times
task[j].getStartDateVar()->setInf(1);
L += *task[j].getEndDateVar();
}
for (j=0;j<NJ;j++) {
for (i=j+1;i<NJ;i++) {
task[i].setupTime(task[j],CLEAN[j][i],CLEAN[i][j]);
}
}
// Cleaning time at end of cycle (between last and first jobs)
firstjob = new KIntVar(problem,"firstjob",1,NJ);
lastjob = new KIntVar(problem,"lastjob",1,NJ);
cleanlf = new KIntVar(problem,"cleanlf",0,1000);
finish = new KIntVar(problem,"finish",0,1000);
problem.post(*firstjob != *lastjob);
for (j=0;j<NJ;j++) {
problem.post( KEquiv( *task[j].getEndDateVar() == *schedule.getMakeSpan(), *lastjob == j+1) );
problem.post( KEquiv( *task[j].getStartDateVar() == 1, *firstjob == j+1) );
}
// Cleaning time after every batch
KEltTerm2D kelt(CLEAN,*firstjob-1,*lastjob-1);
problem.post(new KElement2D(kelt,*cleanlf,"element"));
problem.post(new KMax("max",*finish,L) );
cycleTime = new KIntVar(problem,"finish",0,1000);
// Objective: minimize the duration of a production cycle
problem.post( *cycleTime == *finish - 1 + *cleanlf ) ;
// Solve the problem
schedule.setFunctionPointers(NULL,sfound,NULL,NULL,NULL,&problem);
schedule.setObjective(*cycleTime);
int result = schedule.optimize();
// Solution printing
KIntArray SUCC;
for (j=0;j<NJ;j++) {
SUCC += 0;
for (i=0;i<NJ;i++) {
if (problem.getSolution().getValue(*task[i].getStartDateVar()) == problem.getSolution().getValue(*task[j].getEndDateVar()) + CLEAN[i][j]) {
SUCC[j] = i+1;
}
}
}
printf("Minimum cycle time: %i\n", problem.getSolution().getValue(*cycleTime));
printf("Sequence of batches:\nBatch\tStart\tDur\tCleaning\n");
for (i=0;i<NJ;i++) {
printf(" %i\t%i\t%i\t%i\n",i
,problem.getSolution().getValue(*task[i].getStartDateVar())
,DUR[i]
,SUCC[i] > 0 ? CLEAN[SUCC[i]-1][i]: problem.getSolution().getValue(*cleanlf));
}
from kalis import *
### Data
# Number of paint batches (=jobs)
nb_jobs = 5
# Durations of jobs
jobs_durations = [40, 35, 45, 32, 50]
# Cleaning times between jobs
jobs_cleaning_times = [[0, 11, 7, 13, 11],
[5, 0, 13, 15, 15],
[13, 15, 0, 23, 11],
[9, 13, 5, 0, 3],
[3, 7, 7, 7, 0]]
max_cleaning_time = max(max(jobs_cleaning_times[j]) for j in range(nb_jobs))
### Creation of the problem
# Creation of the Kalis session
session = KSession()
# Creation of the problem in this session
problem = KProblem(session, "B-5 Paint production")
# Creation of the schedule object with time horizon (0..HORIZON)
schedule = KSchedule(problem, "B-5 Paint production Schedule", 0, 10000)
### Variables and constraints creation
# Setting up the resource (formulation of the disjunction of tasks)
resource = KUnaryResource(schedule,"res")
# Setting up the tasks
tasks = KTaskArray()
for j in range(nb_jobs):
tasks += KTask(schedule, "Task%d" % j, jobs_durations[j], resource)
# start times
tasks[j].getStartDateVar().setInf(1)
# Setting up cleaning times
for j in range(nb_jobs):
for i in range(j + 1, nb_jobs):
tasks[i].setupTime(tasks[j], jobs_cleaning_times[j][i], jobs_cleaning_times[i][j])
# Cleaning time at end of cycle (between last and first jobs)
first_job = KIntVar(problem, "firstjob", 0, nb_jobs - 1)
last_job = KIntVar(problem, "lastjob", 0, nb_jobs - 1)
clean_last_first = KIntVar(problem, "cleanlf", 0, 1000)
finish = KIntVar(problem, "finish", 0, 1000)
problem.post(first_job != last_job)
for j in range(nb_jobs):
problem.post(KEquiv(tasks[j].getEndDateVar() == schedule.getMakeSpan(), last_job == j))
problem.post(KEquiv(tasks[j].getStartDateVar() == 1, first_job == j))
# Cleaning time after every batch
# Setting data as a KIntMatrix
K_cleaning_times_matrix = KIntMatrix(nb_jobs, nb_jobs, 0, "CLEAN")
for i in range(nb_jobs):
for j in range(nb_jobs):
K_cleaning_times_matrix.setMatrix(i, j, jobs_cleaning_times[i][j])
# KEltTerm2D constraint:
kelt = KEltTerm2D(K_cleaning_times_matrix, first_job, last_job)
problem.post(KElement2D(kelt, clean_last_first, "element"))
# Setting finish variable
tasks_ends = KIntVarArray()
for j in range(nb_jobs):
tasks_ends += tasks[j].getEndDateVar()
problem.post(KMax("max", finish, tasks_ends))
# Setting up objective
cycle_time = KIntVar(problem, "finish", 0, 1000)
# Objective: minimize the duration of a production cycle
problem.post(cycle_time == (finish - 1 + clean_last_first))
### Solve the problem
# First propagation of the problem
if problem.propagate():
print("Problem is infeasible")
sys.exit(1)
# Run optimization
schedule.setObjective(cycle_time)
result = schedule.optimize()
# Solution printing
if result:
solution = problem.getSolution()
successors = []
for j in range(nb_jobs):
successors.append(-1)
for i in range(nb_jobs):
start_i = solution.getValue(tasks[i].getStartDateVar())
end_j = solution.getValue(tasks[j].getEndDateVar()) + jobs_cleaning_times[i][j]
if start_i == end_j:
successors[j] = i
print("Minimum cycle time: %d" % solution.getValue(cycle_time))
print("Sequence of batches:")
print("Batch\tStart\tDur\tCleaning")
for i in range(nb_jobs):
start_i = solution.getValue(tasks[i].getStartDateVar())
if successors[i] >= 0:
cleaning_time_i = jobs_cleaning_times[successors[i]][i]
else:
cleaning_time_i = solution.getValue(clean_last_first)
print("T%d\t%d\t%d\t%d" % (i + 1, start_i, jobs_durations[i], cleaning_time_i))
// *** Creation of the session
KSession session = new KSession();
// Number of paint batches (=jobs)
int NJ = 5;
// Durations of jobs
int[] DUR = {40, 35, 45, 32, 50};
// Cleaning times between jobs
KIntMatrix CLEAN = new KIntMatrix(5, 5, 0, "CLEAN");
CLEAN.setMatrix(0, 0, 0);
CLEAN.setMatrix(1, 0, 11);
CLEAN.setMatrix(2, 0, 7);
CLEAN.setMatrix(3, 0, 13);
CLEAN.setMatrix(4, 0, 11);
CLEAN.setMatrix(0, 1, 5);
CLEAN.setMatrix(1, 1, 0);
CLEAN.setMatrix(2, 1, 13);
CLEAN.setMatrix(3, 1, 15);
CLEAN.setMatrix(4, 1, 15);
CLEAN.setMatrix(0, 2, 13);
CLEAN.setMatrix(1, 2, 15);
CLEAN.setMatrix(2, 2, 0);
CLEAN.setMatrix(3, 2, 23);
CLEAN.setMatrix(4, 2, 11);
CLEAN.setMatrix(0, 3, 9);
CLEAN.setMatrix(1, 3, 13);
CLEAN.setMatrix(2, 3, 5);
CLEAN.setMatrix(3, 3, 0);
CLEAN.setMatrix(4, 3, 3);
CLEAN.setMatrix(0, 4, 3);
CLEAN.setMatrix(1, 4, 7);
CLEAN.setMatrix(2, 4, 7);
CLEAN.setMatrix(3, 4, 7);
CLEAN.setMatrix(4, 4, 0);
KTaskArray task = new KTaskArray();
KIntVar firstjob = new KIntVar();
KIntVar lastjob = new KIntVar();
KIntVar cleanlf = new KIntVar();
KIntVar finish = new KIntVar();
KIntVarArray L = new KIntVarArray();
// Objective variable
KIntVar cycleTime = new KIntVar();
// Creation of the problem in this session
KProblem problem = new KProblem(session, "B-5 Paint production");
// Creation of the schedule
KSchedule schedule = new KSchedule(problem, "B-5 Paint production Schedule", 0, 10000);
// Setting up the resource (formulation of the disjunction of tasks)
KUnaryResource res = new KUnaryResource(schedule, "res");
// Setting up the tasks
int j, i;
for (j = 0; j < NJ; j++)
{
task.add(new KTask(schedule, "Task" + j + 1, DUR[j], res));
// Start times
task.getElt(j).getStartDateVar().setInf(1);
L.add(task.getElt(j).getEndDateVar());
}
for (j = 0; j < NJ; j++)
{
for (i = j + 1; i < NJ; i++)
{
task.getElt(i).setupTime(task.getElt(j), intp_value(CLEAN.getMatrix(j, i)), intp_value(CLEAN.getMatrix(i, j)));
}
}
// Cleaning time at end of cycle (between last and first jobs)
firstjob = new KIntVar(problem, "firstjob", 1, NJ);
lastjob = new KIntVar(problem, "lastjob", 1, NJ);
cleanlf = new KIntVar(problem, "cleanlf", 0, 1000);
finish = new KIntVar(problem, "finish", 0, 1000);
problem.post(new KNotEqualXyc(firstjob, lastjob, 0));
for (j = 0; j < NJ; j++)
{
problem.post(new KEquiv(new KEqualXyc(task.getElt(j).getEndDateVar(), schedule.getMakeSpan(), 0), new KEqualXc(lastjob, j + 1)));
problem.post(new KEquiv(new KEqualXc(task.getElt(j).getStartDateVar(), 1), new KEqualXc(firstjob, j + 1)));
}
// Cleaning time after every batch
KEltTerm2D kelt = new KEltTerm2D(CLEAN, firstjob, lastjob);
problem.post(new KElement2D(kelt, cleanlf, "element"));
problem.post(new KMax("max", finish, L));
cycleTime = new KIntVar(problem, "finish", 0, 1000);
// Objective: minimize the duration of a production cycle
KLinTerm objComb = new KLinTerm();
objComb.add(cycleTime, 1);
objComb.add(finish, -1);
objComb.add(cleanlf, -1);
problem.post(new KNumLinComb("", objComb.getCoeffs(), objComb.getLvars(), 1, KNumLinComb.LinCombOperator.Equal));
// Solve the problem
schedule.setObjective(cycleTime);
int result = schedule.optimize();
// Solution printing
KIntArray SUCC = new KIntArray();
for (j = 0; j < NJ; j++)
{
for (i = 0; i < NJ; i++)
{
if (problem.getSolution().getValue(task.getElt(i).getStartDateVar()) == problem.getSolution().getValue(task.getElt(j).getEndDateVar()) + intp_value(CLEAN.getMatrix(i, j)))
{
SUCC.add(i + 1);
}
}
}
System.out.println("Minimum cycle time: " + problem.getSolution().getValue(cycleTime));
System.out.print("Sequence of batches:\nBatch\tStart\tDur\tCleaning\n");
for (i = 0; i < NJ; i++)
{
if (i < SUCC.getNumberOfElements() )
{
System.out.println(" " + i + "\t" + problem.getSolution().getValue(task.getElt(i).getStartDateVar()) + "\t" + DUR[i] + "\t" + intp_value(CLEAN.getMatrix(intp_value(SUCC.getElt(i)) - 1, i)));
}
else
{
System.out.println(" " + i + "\t" + problem.getSolution().getValue(task.getElt(i).getStartDateVar()) + "\t" + DUR[i] + "\t" + problem.getSolution().getValue(cleanlf));
}
}
Results¶
The results are similar to those reported in Section 11.5 <kImplies>. It should be noted here that this model formulation is less efficient, in terms of search nodes and running times, than the previous model versions, and in particular the cycle constraint version presented in Section 11.7. However, the task-based formulation is more generic and easier to extend with additional features than the problem-specific formulations in the previous model versions.
The graphical representation as follows (figure Fig. 16).
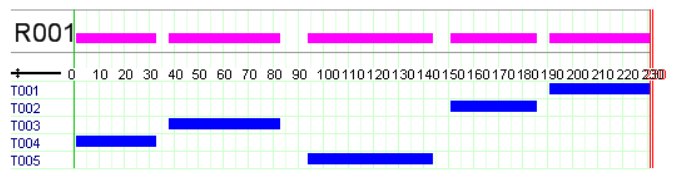
Fig. 16 Solution GANTT¶
Enumeration¶
In the previous scheduling examples we have used the default enumeration for scheduling problems, invoked by the optimization function KSchedule::optimize(). The built-in search strategies used by the solver in this case are particularly suited if we wish to minimize the completion time of a schedule. With other objectives the built-in strategies may not be a good choice, especially if the model contains decision variables that are not part of scheduling objects (the built-in strategies always enumerate first the scheduling objects). Artelys-Kalis makes it therefore possible to use the standard optimization function KSolver::optimize() in models that contain scheduling objects. The default search strategies employed by these optimization functions are different from the scheduling-specific ones and the user may also define his own problem specific enumeration as shown in the following examples.
User-defined enumeration strategies for scheduling problems may take two different forms: variable-based and task-based.
Task-based enumeration¶
A task-based enumeration strategy consists in the definition of a selection strategy choosing the task to be enumerated, a value selection heuristic for the task durations, and a value selection heuristic for the task start times.
Consider once more the problem of planning introduced in Section 12.5 . The behavior of the default scheduling strategy is very poor for this problem so we are going to define a custom search strategy tailored for this problem.
Implementation¶
The following model defines a taskbased branching strategy. We will use a two levels strategy:
First select the task in the first set (because they are the one that provides resource) with the largest remaining domain for its duration variable and enumerate the possible values for this variable starting with the largest.
Then select the other tasks (obtained via the method
KSchedule::getTaskArray()) and apply the same task selection and value selection heuristics as in the first case
A task-based branching strategy is represented in Artelys-Kalis with the branching scheme KTaskSerializer. Several constructors are availables that takes as arguments the user or predefined task selection of type KTaskSelector, value selection strategies for the duration and start variables (standards KValueSelector), and a set of tasks it applies to (represented by the class KTaskArray). Such task-based branching strategies can be combined freely with any variable based branching strategies.
enum JOBS{P1,P2,P3,P4,P5};
char * names[] = {"P1","P2","P3","P4","P5"};
// Limits on job durations
int MIND[] = {3,4,0,4,10};
int MAXD[] = {15,26,15,25,20};
// Resource use/production
int RESAMT[] = {10,12,5,8,7};
// Time horizon
int HORIZON = 35;
// Profit from production
double PROFIT[] = {0,0,5.5,7,6.2};
// Cost of production
double COST[] = {1.8,1.6,0,0,0};
// Available resource quantity
int CAP = 0;
KFloatVar * totalProfit;
// Task objects for jobs
KTaskArray task;
// Non-renewable resource (intermediate prod.)
KDiscreteResource * intermProd;
// Creation of the problem in this session
KProblem problem(session,"Renewable resource");
// Creation of the schedule object with time horizon (0..HORIZON)
KSchedule schedule(problem,"Renewable resource schedule",0,HORIZON);
// Setting up the tasks
int indexJob;
for (indexJob = P1; indexJob <= P5; indexJob ++ ) {
task += * ( new KTask(schedule, names[indexJob],0,HORIZON-MIND[indexJob],MIND[indexJob],MAXD[indexJob]) ) ;
task[indexJob].getEndDateVar()->setSup(HORIZON);
}
// Setting up resources
intermProd = new KDiscreteResource(schedule,"IntP",CAP);
// Providing tasks
for (indexJob = P1; indexJob <= P2; indexJob ++ ) {
task[indexJob].provides(*intermProd,RESAMT[indexJob]);
}
// Requiring tasks
for (indexJob = P3; indexJob <= P5; indexJob ++ ) {
task[indexJob].requires(*intermProd,RESAMT[indexJob]);
}
// Objective function: total profit
totalProfit = new KFloatVar(problem,"totalProfit");
KLinTerm linTerm;
for (indexJob = P3; indexJob <= P5; indexJob ++ ) {
linTerm = linTerm + PROFIT[indexJob] * (*task[indexJob].getDurationVar());
}
for (indexJob = P1; indexJob <= P5; indexJob ++ ) {
linTerm = linTerm - COST[indexJob] * (*task[indexJob].getDurationVar());
}
problem.post(*totalProfit == linTerm);
// closing the schedule
schedule.close();
// propagating problem
if (problem.propagate()) {
printf("Problem is infeasible\n");
exit(1);
}
// maximizing totalProfit
schedule.setObjective(*totalProfit);
schedule.getProblem()->setSense(KProblem::Maximize);
schedule.setFunctionPointers(NULL,sfound,nfound,NULL,NULL,&problem);
if (!USE_DEFAULT_SCHEDULER) {
KBranchingSchemeArray strategy;
KTaskArray first;
first += task[P1];
first += task[P2];
strategy += KTaskSerializer(first,&KLargestDurationDomain(),
&KMaxToMin(),
&KMaxToMin());
strategy += KTaskSerializer(*schedule.getTaskArray(),
&KLargestDurationDomain(),
&KMaxToMin(),
&KMaxToMin());
schedule.setFirstSolutionSearchStrategy(strategy);
schedule.setOptimalSolutionSearchStrategy(strategy);
}
// Find optimal schedule
int result = schedule.optimize();
// Solution printing
printf("Total profit: %f\n", problem.getSolution().getValue(*totalProfit));
printf("Job\tStart\tEnd\tDuration");
for (indexJob = P1; indexJob <= P5; indexJob ++ ) {
printf("%i\t%i\t%i\t%i\n",indexJob,
problem.getSolution().getValue(*task[indexJob].getStartDateVar()),
problem.getSolution().getValue(*task[indexJob].getEndDateVar()),
problem.getSolution().getValue(*task[indexJob].getDurationVar()));
}
from kalis import *
### Data creation
jobs = ["P1", "P2", "P3", "P4", "P5"]
nb_jobs = len(jobs)
providings_jobs_index = [0, 1]
requiring_jobs_index = [2, 3, 4]
# Limits on job durations
min_durations = [3, 4, 0, 4, 10]
max_durations = [15, 26, 15, 25, 20]
# Resource use/production
resource_amounts = [10, 12, 5, 8, 7]
# Time horizon
horizon = 35
# Profit from production
profits = [0, 0, 5.5, 7, 6.2]
# Cost of production
costs = [1.8, 1.6, 0, 0, 0]
# Available resource quantity
capacity = 0
### Creation of the problem
# Creation of the Kalis session
session = KSession()
# Creation of the problem in this session
problem = KProblem(session, "Renewable resource")
# Creation of the schedule object with time horizon (0..HORIZON)
schedule = KSchedule(problem, "Renewable resource schedule", 0, horizon)
### Variables and constraints creation
# Task objects for jobs
tasks = KTaskArray()
for j in range(nb_jobs):
tasks += KTask(schedule, jobs[j], 0, horizon - min_durations[j], min_durations[j], max_durations[j])
tasks[j].getEndDateVar().setSup(horizon)
# Renewable resource (intermediate prod)
intermediate_production = KDiscreteResource(schedule, "IntP", capacity)
# Providing tasks
for j in providings_jobs_index:
tasks[j].provides(intermediate_production, resource_amounts[j])
# Requiring tasks
for j in requiring_jobs_index:
tasks[j].requires(intermediate_production, resource_amounts[j])
# Objective function: total profit
total_profit = KFloatVar(problem ,"totalProfit")
profits_sum = sum((profits[j] - costs[j]) * tasks[j].getDurationVar() for j in range(nb_jobs))
problem.post(total_profit == profits_sum)
# Closing schedule (no tasks or resources can be added after that)
schedule.close()
### Solve the problem
# First propagation of the problem
if problem.propagate():
print("Problem is infeasible")
sys.exit(1)
# Set problem objective and sense
schedule.setObjective(total_profit)
schedule.getProblem().setSense(KProblem.Maximize)
# Setting up task based branching strategy
strategy = KBranchingSchemeArray()
first_jobs = KTaskArray()
for j in providings_jobs_index:
res = first_jobs.add(tasks[j])
strategy += KTaskSerializer(first_jobs, KLargestDurationDomain(),
KMaxToMin(),
KMaxToMin())
strategy += KTaskSerializer(schedule.getTaskArray(),
KLargestDurationDomain(),
KMaxToMin(),
KMaxToMin())
schedule.setFirstSolutionSearchStrategy(strategy)
schedule.setOptimalSolutionSearchStrategy(strategy)
# Find optimal schedule
result = schedule.optimize()
if result:
solution = problem.getSolution()
print("Total profit: %f" % solution.getValue(total_profit))
print("Job\tStart\tEnd\tDuration")
for j in range(nb_jobs):
job_start = solution.getValue(tasks[j].getStartDateVar())
job_end = solution.getValue(tasks[j].getEndDateVar())
job_duration = solution.getValue(tasks[j].getDurationVar())
print("%s\t%d\t%d\t%d" % (jobs[j], job_start, job_end, job_duration))
// Number of jobs and names
int nbJobs = 5;
String[] names = { "P1","P2","P3","P4","P5"};
// Limits on job durations
int MIND[] = { 3, 4, 0, 4, 10 };
int MAXD[] = { 15, 26, 15, 25, 20 };
// Resource use/production
int RESAMT[] = { 10, 12, 5, 8, 7 };
// Time horizon
int HORIZON = 35;
// Profit from production
double PROFIT[] = { 0, 0, 5.5, 7, 6.2 };
// Cost of production
double COST[] = { 1.8, 1.6, 0, 0, 0 };
// Available resource quantity
int CAP = 0;
// Task objects for jobs
KTaskArray task = new KTaskArray();
// Creation of the problem in this session
KProblem problem = new KProblem(session, "Renewable resource");
// Creation of the schedule object with time horizon (0..HORIZON)
KSchedule schedule = new KSchedule(problem, "Renewable resource schedule", 0, HORIZON);
// Setting up the tasks
int indexJob;
for (indexJob = 0; indexJob < nbJobs; indexJob++)
{
task.add(new KTask(schedule, names[indexJob], 0, HORIZON - MIND[indexJob], MIND[indexJob], MAXD[indexJob]));
task.getElt(indexJob).getEndDateVar().setSup(HORIZON);
}
// Setting up non-renewable resource (intermediate prod.)
KDiscreteResource intermProd = new KDiscreteResource(schedule, "IntP", CAP);
// Providing tasks : two first jobs concerned
for (indexJob = 0; indexJob < 2; indexJob++)
{
task.getElt(indexJob).provides(intermProd, RESAMT[indexJob]);
}
// Requiring tasks : three last jobs concerned
for (indexJob = 2; indexJob < nbJobs; indexJob++)
{
task.getElt(indexJob).requires(intermProd, RESAMT[indexJob]);
}
// Objective function: total profit
KFloatVar totalProfit = new KFloatVar(problem, "totalProfit");
KLinTerm linTerm = new KLinTerm();
for (indexJob = 2; indexJob < nbJobs; indexJob++)
{
linTerm.add(task.getElt(indexJob).getDurationVar(),PROFIT[indexJob]);
}
for (indexJob = 0; indexJob < nbJobs; indexJob++)
{
linTerm.add(task.getElt(indexJob).getDurationVar(),- COST[indexJob]);
}
KNumVarArray intVarArrayToSet = linTerm.getLvars();
KDoubleArray coeffsToSet = linTerm.getCoeffs();
intVarArrayToSet.add(totalProfit);
coeffsToSet.add(-1);
problem.post(new KNumLinComb("",coeffsToSet,intVarArrayToSet,0,KNumLinComb.LinCombOperator.Equal));
// closing the schedule
schedule.close();
// propagating problem
if (problem.propagate())
{
System.out.println("Problem is infeasible");
exit(1);
}
// maximizing totalProfit
schedule.setObjective(totalProfit);
schedule.getProblem().setSense(KProblem.Sense.Maximize);
if (!USE_DEFAULT_SCHEDULER)
{
KBranchingSchemeArray strategy = new KBranchingSchemeArray();
KTaskArray first = new KTaskArray();
first.add(task.getElt(0));
first.add(task.getElt(1));
strategy.add(new KTaskSerializer(first, new KLargestDurationDomain(), new KMaxToMin(), new KMaxToMin()));
strategy.add(new KTaskSerializer(schedule.getTaskArray(), new KLargestDurationDomain(), new KMaxToMin(), new KMaxToMin()));
schedule.setFirstSolutionSearchStrategy(strategy);
schedule.setOptimalSolutionSearchStrategy(strategy);
}
// Find optimal schedule
schedule.optimize();
// Solution printing
System.out.println("Total profit: " + problem.getSolution().getValue(totalProfit));
System.out.print("Job\tStart\tEnd\tDuration\n");
for (indexJob = 0; indexJob < nbJobs; indexJob++)
{
System.out.println(indexJob + "\t" + problem.getSolution().getValue(task.getElt(indexJob).getStartDateVar()) + "\t" + problem.getSolution().getValue(task.getElt(indexJob).getEndDateVar()) + "\t" + problem.getSolution().getValue(task.getElt(indexJob).getDurationVar()));
}
Results¶
An optimal solution to this problem has an objective of 288.1. In comparison with the default scheduling strategy, our branching strategy reduces drastically the number of nodes that are enumerated and is able to prove optimality within a few seconds. A first solution is found immediately in 9 nodes with objective 281.9 and a second solution with a total profit of 288.1 if found in 8 more nodes. The scheduler enumerate then all the possibilities to prove optimality. Running the model results in the solution shown below:

Fig. 17 Solution enumeration task-based¶
Multi-machines Disjunctive scheduling¶
Consider the typical definition of a job-shop scheduling problem: we are given a set of jobs that needs to be processed in a fixed order by a given set of machines. A machine executes one job at a time. The durations of the production tasks (= processing of a job on a machine) and the sequence of machines per job for a 6 × 6 instance are shown in following table. The objective is to minimize the makespan (latest completion time) of the schedule.
Fig. 18 6 x 6 Jobshop instance¶
Model formulation¶
Let denote the set of jobs and 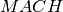 (
(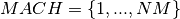 ) the set of machines. Every job is produced as a sequence of tasks
) the set of machines. Every job is produced as a sequence of tasks 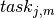 where needs to be finished before
where needs to be finished before 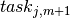 can start. A task is processed by the machine
can start. A task is processed by the machine 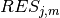 and has a fixed duration
and has a fixed duration 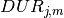 . The following model formulates the job-shop scheduling problem.
. The following model formulates the job-shop scheduling problem.
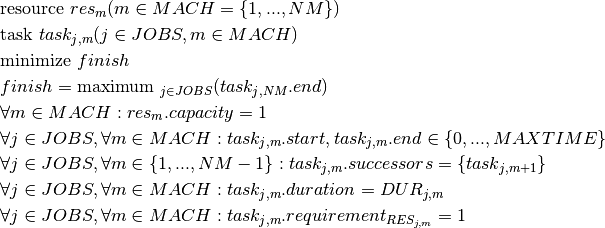
Implementation¶
The following model implements the job-shop scheduling problem:
// *** Modeling of the problem
// Creation of the problem in this session
KProblem problem(session,"JobShop CSP");
KSchedule s(problem,"JobShop Schedule",0,10000);
// Declaration and creation of the array keeping start dates of all tasks assigned to each job
KTask *** tasks = new KTask**[nbJobs];
KUnaryResource ** resources = new KUnaryResource*[nbRes];
int indexJob;
int indexRes;
for(indexRes = 0; indexRes < nbRes; indexRes++)
{
char name[20];
sprintf(name,"machine_%i",indexRes);
resources[indexRes] = new KUnaryResource(s,name);
}
for (indexJob = 0; indexJob < nbJobs; indexJob++)
{
tasks[indexJob] = new KTask*[nbRes];
for(indexRes = 0; indexRes < nbRes; indexRes++)
{
char name[20];
sprintf(name,"T%i_J%i",indexRes,indexJob);
tasks[indexJob][indexRes] = new KTask(s,name,0,s.getTimeMax(),
taskDuration[indexJob][indexRes],
taskDuration[indexJob][indexRes]);
tasks[indexJob][indexRes]->useResource(
*resources[taskUse[indexJob][indexRes]],1);
}
}
// constraints creation
for (indexJob = 0; indexJob < nbJobs; indexJob++)
{
for(int indexRes = 0; indexRes < nbRes - 1; indexRes++)
{
//posting Precedence constraints between the tasks of a same JOB
tasks[indexJob][indexRes+1]->startsAfter(*tasks[indexJob][indexRes]);
}
}
s.setFunctionPointers(NULL,solution_found,NULL,NULL,NULL,&problem);
s.optimize();
// solution resume
s.getProblem()->getSolution().printResume();
### Modeling of the problem
# Creation of the problem in this session
problem = KProblem(session, "JobShop CSP")
schedule = KSchedule(problem, "JobShop Schedule", 0, 10000)
# Declaration and creation of the array keeping start dates of all tasks assigned to each job
resources = []
for r in range(nb_resources):
resources.append(KUnaryResource(schedule, "machine_%d" % r))
tasks = []
for j in range(nb_jobs):
tasks.append([])
for r in range(nb_resources):
tasks[j].append( KTask(schedule, "T%d_J%d" % (r, j), schedule.getTimeMax(),
task_duration[j][r],
task_duration[j][r]))
tasks[j][r].useResource(resources[machine_used[j][r]], 1)
# posting precedence constraints between the tasks of a same job
for j in range(nb_jobs):
for r in range(nb_resources - 1):
tasks[j][r + 1].startsAfter(tasks[j][r])
# Run optimization
schedule.optimize()
# solution resume
schedule.getProblem().getSolution().printResume()
// Creation of the problem in this session
KProblem problem = new KProblem(session,"JobShop CSP");
KSchedule s= new KSchedule(problem, "JobShop Schedule",0,10000);
// Declaration and creation of the array keeping start dates of all tasks assigned to each job
KTask[][] tasks = new KTask[nbJobs][];
KUnaryResource[] resources = new KUnaryResource[nbRes];
int indexJob;
int indexRes;
for(indexRes = 0; indexRes < nbRes; indexRes++)
{
resources[indexRes] = new KUnaryResource(s,"machine_" + indexRes);
}
for (indexJob = 0; indexJob < nbJobs; indexJob++)
{
tasks[indexJob] = new KTask[nbRes];
for(indexRes = 0; indexRes < nbRes; indexRes++)
{
tasks[indexJob][indexRes] = new KTask(s,"T" + indexRes + "_J" + indexJob,0,s.getTimeMax(),taskDuration[indexJob][indexRes],taskDuration[indexJob][indexRes]);
tasks[indexJob][indexRes].useResource(resources[taskUse[indexJob][indexRes]],1);
}
}
// constraints creation
for (indexJob = 0; indexJob < nbJobs; indexJob++)
{
for(indexRes = 0; indexRes < nbRes - 1; indexRes++)
{
//posting Precedence constraints between the tasks of a same JOB
tasks[indexJob][indexRes+1].startsAfter(tasks[indexJob][indexRes]);
}
}
s.optimize();
// solution resume
s.getProblem().getSolution().printResume();
Resource usage¶
A resource usage is a means to specify the way that a resource will be produced / consumed / provided / required by a task. Three types of resource usages can be used:
Fig. 20 Different resource usages¶
case 1: Constant resource usage. This is the simplest case where the resource usage is constant all along the execution of the task. For example a task A will require 2 units of resource R during its execution.
case 2: Variable resource usage but constant over the execution of the task. This case allows the resource usage to be variable but constant during the execution of the task. Therefore, a decision variable is associated with the resource usage that can be constrained like any other variable. For example a task A will require between 2 units and 4 units of resource R during its execution.
case 3: Variable resource usage over the execution of the task. This case allows the resource usage to vary during the execution of the task using a resource usage profile defined as a
KIntArray. For example, a task A will require [2,3,2,3,2,1,2,1] resource units wich means ’2’ for the first timestep of its execution; ’3’ for the second etc.. If the duration of the task exceeds the length of the profile, then the resource usage is considered as 0 after the end of the profile. If the task duration is smaller than the length of the profile, the profile will be truncated to the duration of the task.
Model formulation¶
Let  be the set of tasks and the duration of . Let a resource of capacity
be the set of tasks and the duration of . Let a resource of capacity  required by all tasks for their execution and
required by all tasks for their execution and  the resource usage profile of . With the objective of minimizing the makespan of the schedule we may formulate the model as follows.
the resource usage profile of . With the objective of minimizing the makespan of the schedule we may formulate the model as follows.

Implementation¶
The following model defines the explained model above, using a KResourceUsage to set the requirement constraint.
// Number of tasks
int nbTasks = 4;
// Duration of tasks
int duration[4] = { 7, 9, 8, 5 };
// Resource used profile per task
int profiles[][9] = { { 12, 12, 6, 2, 2, 2, 2 },
{ 12, 12, 6, 2, 2, 2, 2, 2, 2 },
{ 12, 12, 3, 3, 3, 3, 3, 3 },
{ 6, 6, 6, 6, 6 } };
// Resource capacity
int resCapacity = 18;
// Creation of the problem in this session
KProblem problem(session, "Variable resource usage");
// Time horizon
int horizon = 0;
for (int dur : duration) {
horizon += dur;
}
// Creation of the schedule object with time horizon (0..horizon)
KSchedule schedule(problem, "Variable resource usage schedule", 0, horizon);
// Tasks to be planned
KTaskArray tasks;
int indexTask;
// building each task with fixed duration
for (indexTask = 0; indexTask < nbTasks; indexTask++) {
std::stringstream sout("");
sout << "task_" << indexTask;
tasks += KTask(schedule, sout.str().c_str(), duration[indexTask]);
}
// Creation of the resource
KDiscreteResource res(schedule, "resource", resCapacity);
// Requirement on the task indicating the resource usage
for (indexTask = 0; indexTask < nbTasks; indexTask++) {
KIntArray profile_array;
for (int step = 0; step < duration[indexTask]; step++) {
profile_array += profiles[indexTask][step];
}
profile_array.print();
tasks[indexTask].requires(KResourceUsage(res, profile_array));
}
// Minimize the makespan
schedule.optimize();
// solution printing
problem.getSolution().print();
nb_tasks = 4
duration = [7, 9, 8, 5]
horizon = 0
for dur in duration:
horizon += dur
# Resource used profile per task
profile = [[12, 12, 6, 2, 2, 2, 2],
[12, 12, 6, 2, 2, 2, 2, 2, 2],
[12, 12, 3, 3, 3, 3, 3, 3],
[6, 6, 6, 6, 6]]
res_capacity = 18
# Creation of the problem in this session
problem = KProblem(session, "Variable resource usage")
# Creation of the schedule object with time horizon (0..horizon)
schedule = KSchedule(problem, "Variable resource usage schedule", 0, horizon)
# Tasks to be planned
tasks = KTaskArray()
# building each task with fixed duration
for i in range(nb_tasks):
tasks += KTask(schedule, "task_%d" % i, duration[i])
# Creation of the resource
res = KDiscreteResource(schedule, "resource", res_capacity)
# Requirement on the task indicating the resource usage
for i in range(nb_tasks):
profile_array = KIntArray()
for elem in profile[i]:
profile_array.add(elem)
tasks[i].requires(KResourceUsage(res, profile_array))
### Minimize the makespan
result = schedule.optimize()
# solution printing
problem.getSolution().display()
// Number of tasks
int nbTasks = 4;
// Duration of tasks
int[] duration = {7, 9, 8, 5};
// Resource used profile per task
int[][] profiles = { {12, 12, 6, 2, 2, 2, 2},
{12, 12, 6, 2, 2, 2, 2, 2, 2},
{12, 12, 3, 3, 3, 3, 3, 3},
{6, 6, 6, 6, 6} };
// Resource capacity
int resCapacity = 18;
// Creation of the problem
KProblem problem = new KProblem(session,"Variable resource usage");
int horizon = 0;
for (int dur : duration) {
horizon += dur;
}
// Creation of the schedule
KSchedule schedule = new KSchedule(problem, "Variable resource usage schedule", 0, horizon);
// Tasks to be planned
KTask[] tasks = new KTask[nbTasks];
int indexTask;
// building each tasks with fixed duration
for (indexTask = 0; indexTask < nbTasks; indexTask++) {
tasks[indexTask] = new KTask(schedule, "task_" + indexTask, duration[indexTask]);
}
// Creation of the resource
KDiscreteResource res = new KDiscreteResource(schedule, "resource", resCapacity);
for (indexTask = 0; indexTask < nbTasks; indexTask++) {
KIntArray profile_array = new KIntArray();
for (int elem: profiles[indexTask]) {
profile_array.add(elem);
}
tasks[indexTask].requires(new KResourceUsage(res, profile_array));
}
// Minimize the makespan
schedule.optimize();
// solution resume
schedule.getProblem().getSolution().printResume();
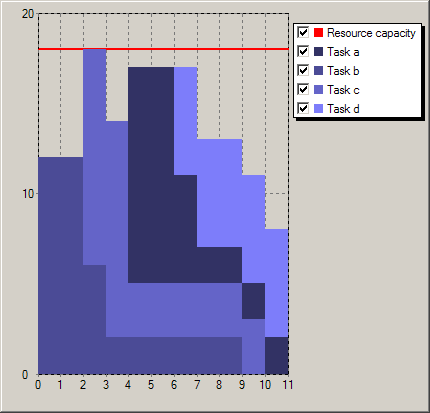
Branching strategy¶
When using KSchedule::optimize(), the search algorithm is decomposed in two distinct phases. The first phase targets the finding of an near optimal heuristic solution quickly. The second and last phase focuses on improving the bound and prove optimality.
Thus, users have to specify the phase for which they set the custom branching scheme. They can set one for either phase or both phases.
In order to always have a meaningful branching scheme, some default strategies are implemented and used if no other branching strategy is defined in the model. These default strategies depend on the type of scheduling:
Disjunctive scheduling: if all the resources used in the model are unary resources, then the default strategy for both phases is based on a
KSettleDisjunctionscheme (see Section 6.1). However if the unary resources are used as alternative resources, then the second default strategy used (see below).Cumulative scheduling: in this case, the default strategy for both phases uses a
KAssignAndForbid(see Section 6.1) to set all the affectation variables on tasks and then aKTaskSerializer(see above) to instantiate the remaining tasks by instantiating their start and duration. The difference between the strategies of the first and second phase is in theKVariableSelectorused in theKAssignAndForbidscheme. Indeed, during the first phase, aKRandomVariableis used whereas during the second phase, aKInputOrderis used.